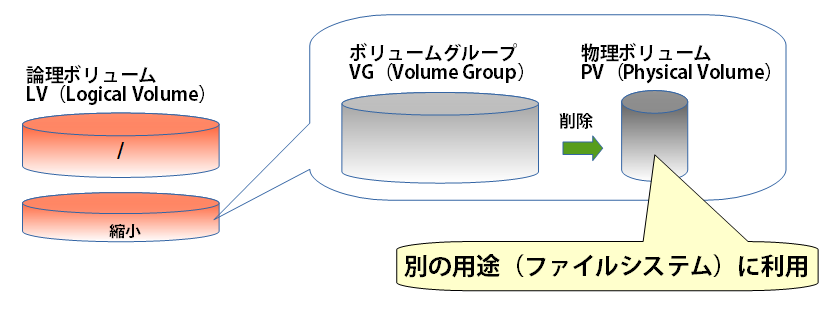
第5回に引き続き、Linuxなどのストレージを柔軟に管理する仕組み「LVM」(Logical Volume Manager)の利点を紹介します。今回は「スナップショット」です。
このスナップショットは、LVMの「論理ボリューム」を瞬時にバックアップできるとても便利な機能です(図1)。スナップショット作成時の論理ボリューム(LV)の状態を維持でき、それを「dump」や「rsync」などのコマンドで簡単に取り出せます。
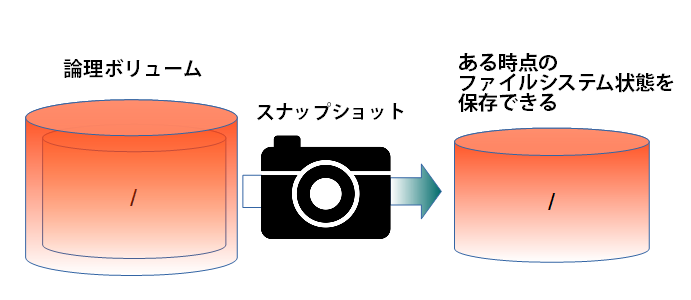
図1 スナップショット機能
test
第5回に引き続き、Linuxなどのストレージを柔軟に管理する仕組み「LVM」(Logical Volume Manager)の利点を紹介します。今回は「スナップショット」です。
このスナップショットは、LVMの「論理ボリューム」を瞬時にバックアップできるとても便利な機能です(図1)。スナップショット作成時の論理ボリューム(LV)の状態を維持でき、それを「dump」や「rsync」などのコマンドで簡単に取り出せます。
図1 スナップショット機能
著者:米田
シェルスクリプトマガジンでは、小型コンピュータボード「Raspberry Pi」(ラズパイ)のプログラミングが楽しめる拡張ボード「ラズパイ入門ボード」を制作しました。本連載では、ラズパイ入門ボードを使った電子回路制御を取り上げていきます。第2 回は、Grove System の光センサーを扱います。
記事本文掲載のシェルスクリプトマガジンvol.54は以下のリンク先でご購入できます。
![]()
![]()
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
import time import Adafruit_GPIO.SPI as SPI import Adafruit_SSD1306 from PIL import Image from PIL import ImageDraw from PIL import ImageFont class OLED(): OLED_WIDTH = 128 OLED_HEIGHT = 64 RST = 24 DC = 23 SPI_PORT = 0 SPI_DEVICE = 0 DEFAULT_FONT = '/usr/share/fonts/truetype/fonts-japanese-gothic.ttf' FONT_SIZE = 14 _LINE_HEIGHT = 16 def __init__(self, port=SPI_PORT, dev=SPI_DEVICE, _rst=RST, _dc=DC): self._spi = SPI.SpiDev(port, dev, max_speed_hz=8000000) self._disp = Adafruit_SSD1306.SSD1306_128_64(rst=_rst, dc=_dc, spi=self._spi) self._disp.begin() self._disp.clear() self._disp.display() self._image = Image.new('1', (self.OLED_WIDTH, self.OLED_HEIGHT) ,0) self._draw = ImageDraw.Draw(self._image) self._font = ImageFont.truetype(self.DEFAULT_FONT, self.FONT_SIZE, encoding='unic') def put_string(self, str, line=0): self._draw.rectangle((0, line*self._LINE_HEIGHT, self.OLED_WIDTH,line*self._LINE_HEIGHT+self._LINE_HEIGHT), fill=(0)) self._draw.text((0, line*self._LINE_HEIGHT), str, font=self._font, fill=1) self._disp.image(self._image) self._disp.display() |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
#!/usr/bin/python3 # -*- coding: utf-8 -*- from tsl2561 import TSL2561 from OLED import OLED import time oled = OLED() # アドレスを指定する tsl = TSL2561(address=0x29) oled.put_string('Current LUX') while True: # lux()メソッドで現在の照度を得ることが出来る oled.put_string(str(tsl.lux()), 1) time.sleep(1) |
著者:大内 智明
ユニケージでは、小さな道具の「コマンド」をシェルスクリプトで組み合わせて、さまざまな業務システムを構築しています。本連載では、毎回あるテーマに従ってユニケージによるシェルスクリプトの記述例を分かりやすく紹介します。初回は、サーバー2重化時のデータ書き込みです。
記事本文掲載のシェルスクリプトマガジンvol.54は以下のリンク先でご購入できます。
![]()
![]()
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
#!/bin/ush -xve (略) err ERROR_EXIT(){ exit 1 } (略) if [ -z $(msctrl -job HACHU -ctrl C -msflg M -print host) ] ; then ERROR_EXIT else set +e err true touch ${lv1d}/touchfile [ $? -eq 0 ] || echo "AP1" >> $tmp-cp-err err ERROR_EXIT set -e if [ -s $tmp-cp-err ];then errcnt=$(lineup 1 $tmp-cp-err | gyo) [ "${errcnt}" -eq "1" ] && ERROR_EXIT fi set +e err true 正サーバーへのデータ書き込み処理(記述例) ファイルを書き込むコマンド [ $? -eq 0 ] || echo "AP1" >> $tmp-cp-err err ERROR_EXIT set -e if [ -s $tmp-cp-err ];then errcnt=$(lineup 1 $tmp-cp-err | gyo) [ "${errcnt}" -eq "1" ] && ERROR_EXIT fi if [ -z $(msctrl -job HACHUBT -ctrl C -msflg S -print host) ] ; then : else set +e err true 副サーバーへの書き込み処理(記述例) ファイルを書き込むコマンド [ $? -eq 0 ] || echo "AP2" >> $tmp-cp-err err ERROR_EXIT set -e if [ -s $tmp-cp-err ];then errcnt=$(lineup 1 $tmp-cp-err | gyo) [ "${errcnt}" -eq "1" ] && ワーニング処理 fi fi fi |
著者:後藤 大地
前回までの2回で、XMLパーサーライブラリ「expat」の使い方と、expatによるXMLデータをJSONデータへ変換する方法を取り上げた。前回作成したサンプルコードはとりあえず動作するものだが、それほどきれいに整理はされていない。今回はこのサンプルコードを整理して完成させる。
記事本文掲載のシェルスクリプトマガジンvol.54は以下のリンク先でご購入できます。
![]()
![]()
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
#include "xml2json.h" int main(int argc, char *argv[]) { char buf[BUFSIZ]; int len, done; XML_Parser parser = XML_ParserCreate(NULL); XML_SetElementHandler(parser, begin, end); XML_SetCharacterDataHandler(parser, chardata); do { len = fread(buf, 1, sizeof(buf), stdin); done = len < sizeof(buf); if (XML_Parse(parser, buf, (int)len, done) == XML_STATUS_ERROR) return 1; } while (!done); XML_ParserFree(parser); return 0; } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
typedef enum __element_type { TYPE_STRUCTURE, TYPE_KEY, TYPE_VALUE, TYPE_NOT_APPLICABLE } ELEMENT_TYPE; typedef enum __element { ELEMENT_DOCUMENT, ELEMENT_DOCGROUP, ELEMENT_DOCINFO, ELEMENT_TITLE, ELEMENT_AUTHOR, ELEMENT_FIRSTEDITION, ELEMENT_LASTMODIFIED, ELEMENT_P, ELEMENT_NOT_APPLICABLE } ELEMENT; typedef struct __element_info { ELEMENT_TYPE element_type; ELEMENT element; char* name; } ELEMENT_INFO; |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
#include "xml2json.h" static const ELEMENT_INFO ELEMENTS_INFO[] = { { TYPE_STRUCTURE, ELEMENT_DOCUMENT, "document" }, { TYPE_STRUCTURE, ELEMENT_DOCGROUP, "docgroup" }, { TYPE_STRUCTURE, ELEMENT_DOCINFO, "docinfo" }, { TYPE_KEY, ELEMENT_TITLE, "title" }, { TYPE_KEY, ELEMENT_AUTHOR, "author" }, { TYPE_KEY, ELEMENT_FIRSTEDITION, "firstedition" }, { TYPE_KEY, ELEMENT_LASTMODIFIED, "lastmodified" }, { TYPE_VALUE, ELEMENT_P, "p" }, { TYPE_NOT_APPLICABLE, ELEMENT_NOT_APPLICABLE, NULL } }; ELEMENT_TYPE name_2_element_type(const XML_Char *name) { int i = 0; while (ELEMENTS_INFO[i].element != ELEMENT_NOT_APPLICABLE) { if (0 == strcmp(ELEMENTS_INFO[i].name, name)) return ELEMENTS_INFO[i].element_type; i++; } return TYPE_NOT_APPLICABLE; } ELEMENT_TYPE element_2_element_type(ELEMENT element) { int i = 0; while (ELEMENTS_INFO[i].element != ELEMENT_NOT_APPLICABLE) { if (ELEMENTS_INFO[i].element == element) return ELEMENTS_INFO[i].element_type; i++; } return TYPE_NOT_APPLICABLE; } ELEMENT name_2_element(const XML_Char *name) { int i = 0; while (ELEMENTS_INFO[i].element != ELEMENT_NOT_APPLICABLE) { if (0 == strcmp(ELEMENTS_INFO[i].name, name)) return ELEMENTS_INFO[i].element; i++; } return ELEMENT_NOT_APPLICABLE; } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
#include <sys/queue.h> #include <stdlib.h> #include <malloc_np.h> #include "xml2json.h" static int initialized = 0; static struct slisthead *headp; static struct entry { ELEMENT element; SLIST_ENTRY(entry) entries; } *np; SLIST_HEAD(slisthead, entry) head = SLIST_HEAD_INITIALIZER(head); static void init(void); void stack_push(ELEMENT element) { init(); np = malloc(sizeof(struct entry)); np->element = element; SLIST_INSERT_HEAD(&head, np, entries); } void stack_pop(void) { init(); np = SLIST_FIRST(&head); SLIST_REMOVE_HEAD(&head, entries); free(np); } ELEMENT stack_top(void) { init(); np = SLIST_FIRST(&head); if (NULL == np) return ELEMENT_NOT_APPLICABLE; return (SLIST_FIRST(&head)->element); } static void init(void) { if (!initialized) { SLIST_INIT(&head); initialized = 1; } } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 |
#include "xml2json.h" static void indent(void); static int depth = 0; static ELEMENT pre_element; static ELEMENT_TYPE pre_type; static int pre_element_is_start_tag; void XMLCALL begin(void *d, const XML_Char *name, const XML_Char **attr) { ELEMENT element = name_2_element(name); ELEMENT_TYPE type = name_2_element_type(name); ELEMENT parent = stack_top(); ELEMENT_TYPE parent_type = element_2_element_type(parent); switch (element) { case ELEMENT_DOCUMENT: printf("{"); break; default: switch (type) { case TYPE_STRUCTURE: switch (element) { case ELEMENT_DOCUMENT: printf("{ "); break; default: if (pre_element_is_start_tag) printf("\n"); else printf(",\n"); break; } indent(); printf("\"%s\": {", name); break; case TYPE_KEY: switch (pre_type) { case TYPE_KEY: printf(","); break; default: break; } printf("\n"); indent(); printf("\"%s\":", name); break; case TYPE_VALUE: switch (parent_type) { case TYPE_KEY: putchar('"'); break; default: if (pre_element_is_start_tag) printf("\n"); else printf(",\n"); indent(); printf("\"content\":\""); break; } break; default: break; } break; } ++depth; pre_element = element; pre_type = type; pre_element_is_start_tag = 1; stack_push(element); } void XMLCALL end(void *d, const XML_Char * name) { --depth; ELEMENT_TYPE type = name_2_element_type(name); ELEMENT element = name_2_element(name); switch (element) { case ELEMENT_DOCUMENT: printf("\n}\n"); break; default: switch (type) { case TYPE_STRUCTURE: printf("\n"); indent(); printf("}"); break; case TYPE_KEY: break; case TYPE_VALUE: putchar('"'); break; default: break; } break; } pre_element = element; pre_type = type; pre_element_is_start_tag = 0; stack_pop(); } void chardata(void *data, const XML_Char *cdata, int len) { char *p; switch (stack_top()) { case ELEMENT_P: p = (char *)cdata; for (int i = 0; i < len; i++) if ('\n' != *p) putchar(*p++); break; default: break; } } static void indent() { for (int i = 0; i < depth; i++) printf("\t"); } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
#include <stdio.h> #include <string.h> #include <expat.h> typedef enum __element_type { TYPE_STRUCTURE, TYPE_KEY, TYPE_VALUE, TYPE_NOT_APPLICABLE } ELEMENT_TYPE; typedef enum __element { ELEMENT_DOCUMENT, ELEMENT_DOCGROUP, ELEMENT_DOCINFO, ELEMENT_TITLE, ELEMENT_AUTHOR, ELEMENT_FIRSTEDITION, ELEMENT_LASTMODIFIED, ELEMENT_P, ELEMENT_NOT_APPLICABLE } ELEMENT; typedef struct __element_info { ELEMENT_TYPE element_type; ELEMENT element; char* name; } ELEMENT_INFO; void XMLCALL begin(void *, const XML_Char*, const XML_Char**); void XMLCALL end(void *, const XML_Char *); void XMLCALL chardata(void *, const XML_Char *, int); ELEMENT_TYPE name_2_element_type(const XML_Char *); ELEMENT_TYPE element_2_element_type(ELEMENT); ELEMENT name_2_element(const XML_Char *); void stack_push(ELEMENT); void stack_pop(void); ELEMENT stack_top(void); |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
CC= cc RM= rm -f EXPAT= -lexpat LIBDIR= /usr/local/lib INCLUDEDIR= /usr/local/include CFLAGS= -I${INCLUDEDIR} -L${LIBDIR} ${EXPAT} SRCS= xml2json.c element.c process.c stack.c OUT= xml2json OBJS= ${SRCS:C,.c$,.o,} .c.o: ${CC} -I${INCLUDEDIR} -c $< build: ${OBJS} ${CC} -o ${OUT} ${CFLAGS} ${OBJS} clean: ${RM} ${OUT} ${OBJS} |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
<?xml version="1.0" encoding="UTF-8"?> <document> <docgroup> <docinfo> <title><p>タイトル</p></title> <author><p>名前</p></author> <firstedition><p>編集開始日</p></firstedition> <lastmodified><p>編集終了日</p></lastmodified> </docinfo> <docgroup> <docinfo> <title><p>章タイトル</p></title> </docinfo> <p>説明1</p> <p>説明2</p> </docgroup> </docgroup> </document> |
著者:楠目幹
こんにちは。香川大学工学部 学部4年生の楠目です。高校時代にPCがマルウェアに感染した経験がきっかけでセキュリティに興味を持ち、マルウェア対策やペネトレーションテストに関する分野の勉強を行っています。
昨年の8月「セキュリティ・キャンプ全国大会2017」に参加しました。そこでは「Linux向けマルウェア対策ソフトを作ろう」と言う講義に参加し、「surface indicator+αなELFマルウェアの分類」というテーマに、チームで取り組みました。このテーマの目標は、機械学習や複雑な解析を用いずにELFマルウェアの亜種を素早く検出することです。今回の記事では、私が講師やチューターの方、チームのメンバーと一緒に取り組んだ内容をご紹介します。
![]()
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
#! /usr/bin/env python3 # VirusTotalのメタデータから特定のアンチウィルスソフトウェアで特定の検出名を持つものを出力 # Usage: ./z2kit_find_virustotal.py import glob import json import sys import z2kit.elf import z2kit.features AV_SOFTWARE = '指定したアンチウィルスソフトウェア' EXPECTED_DETECTION = '対応する検体名' def set_features(elffile): if not isinstance(elffile, z2kit.elf.ELFFile): raise ValueError('ELFFileクラスを与えなければなりません。') elffile.features = {} elffile.features['md5'] = z2kit.features.MD5Feature().get_feature(elffile) elffile.features['ssdeep'] = z2kit.features.SsdeepFeature().get_feature(elffile) elffile.features['lstrfuzzy'] = z2kit.features.LstrfuzzyFeature().get_feature(elffile) with open('virustotal-ELF-VXShare.json') as f: virustotal_info = json.load(f) for filename in glob.glob('z2/VirusShare_*'): try: elffile = z2kit.elf.ELFFile.read_from_file(filename) set_features(elffile) md5 = elffile.features['md5'] if md5 not in virustotal_info: continue if AV_SOFTWARE not in virustotal_info[md5]['scans']: continue if not virustotal_info[md5]['scans'][AV_SOFTWARE]['detected']: continue if virustotal_info[md5]['scans'][AV_SOFTWARE]['result'] != EXPECTED_DETECTION: continue print(filename) except: raise |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
#! /usr/bin/env python3 # ファイルリストを受け取ってlstrfuzzyデータを出力 # Usage: ./z2kit_extract_lstrfuzzy.py FILELIST import sys import z2kit.elf import z2kit.features def set_features(elffile): if not isinstance(elffile, z2kit.elf.ELFFile): raise ValueError('ELFファイルを与えなければなりません。') elffile.features = {} elffile.features['md5'] = z2kit.features.MD5Feature().get_feature(elffile) elffile.features['ssdeep'] = z2kit.features.SsdeepFeature().get_feature(elffile) elffile.features['lstrfuzzy'] = z2kit.features.LstrfuzzyFeature().get_feature(elffile) with open(sys.argv[1], 'r') as f: for ln in f: filename = ln[:-1] try: elffile = z2kit.elf.ELFFile.read_from_file(filename) set_features(elffile) print(filename, elffile.features['lstrfuzzy']) except: pass |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
#! /usr/bin/env python3 # z2kit_extract_lstrfuzzy.pyの結果をもとに検出器を作成する # 検出器を使った結果とz2kit_find_virustotal.pyとの結果を比較する # Usage: ./z2_find_match.py import glob import json import sys import z2kit.elf import z2kit.features import ssdeep AV_SOFTWARE = '指定したアンチウィルスソフトウェア' EXPECTED_DETECTION = '対応する検体名' def set_features(elffile): if not isinstance(elffile, z2kit.elf.ELFFile): raise ValueError('ELFFile クラスを与えなければなりません。') elffile.features = {} elffile.features['md5'] = z2kit.features.MD5Feature().get_feature(elffile) elffile.features['ssdeep'] = z2kit.features.SsdeepFeature().get_feature(elffile) elffile.features['lstrfuzzy'] = z2kit.features.LstrfuzzyFeature().get_feature(elffile) def is_malware_to_focus(elffile): return \ ssdeep.compare(elffile.features['lstrfuzzy'], '選出したハッシュ値') >= 50 or \ ssdeep.compare(elffile.features['lstrfuzzy'], '選出したハッシュ値') >= 50 or \ ssdeep.compare(elffile.features['lstrfuzzy'], '選出したハッシュ値') >= 50 for filename in glob.glob('z2/VirusShare_*'): try: elffile = z2kit.elf.ELFFile.read_from_file(filename) set_features(elffile) if is_malware_to_focus(elffile): print(filename) except: pass |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
#! /usr/bin/env python3 # stringsコマンドの結果を特徴量とする # Usage: ./z2kit_find_strings_by_virustotal.py | ./histogram_to_graph.py /dev/stdin > TEXT import glob import json import sys import z2kit.elf import z2kit.features AV_SOFTWARE = '指定したアンチウィルスソフトウェア' EXPECTED_DETECTION = '対応する検体名' def set_features(elffile): if not isinstance(elffile, z2kit.elf.ELFFile): raise ValueError('ELFFile クラスを与えなければなりません。') elffile.features = {} elffile.features['md5'] = z2kit.features.MD5Feature().get_feature(elffile) #elffile.features['ssdeep'] = z2kit.features.SsdeepFeature().get_feature(elffile) #elffile.features['lstrfuzzy'] = z2kit.features.LstrfuzzyFeature().get_feature(elffile) elffile.features['strings'] = z2kit.features.StringsFeature().get_feature(elffile) with open('virustotal-ELF-VXShare.json') as f: virustotal_info = json.load(f) HISTOGRAM = {} for filename in glob.glob('z2/VirusShare_*'): try: elffile = z2kit.elf.ELFFile.read_from_file(filename) set_features(elffile) md5 = elffile.features['md5'] if md5 not in virustotal_info: continue if AV_SOFTWARE not in virustotal_info[md5]['scans']: continue if not virustotal_info[md5]['scans'][AV_SOFTWARE]['detected']: continue if virustotal_info[md5]['scans'][AV_SOFTWARE]['result'] != EXPECTED_DETECTION: continue strings = elffile.features['strings'] for s in strings.keys(): if s not in HISTOGRAM: HISTOGRAM[s] = 0 HISTOGRAM[s] += strings[s] except: pass json.dump(HISTOGRAM, sys.stdout) #! /usr/bin/env python3 # JSONファイルをもとにヒストグラムを作成 # Usage: ./histogram_to_graph.py JSON_FILE import json import sys WIDTH = 40 FILLER = '#' with open(sys.argv[1], 'r', encoding='utf-8') as f: obj = json.load(f) m = 0 for v in obj.values(): m = max(v, m) FORMAT = '{}{} {:' + str(len(str(m))) + 'd} {}' for i, v in sorted(obj.items(), key=lambda x:-x[1]): g = int((WIDTH - 1) * 1.0 * v / m) g = FILLER * g + ' ' * (WIDTH - 1 - g) print(FORMAT.format(FILLER, g, v, i)) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
#! /usr/bin/env python3 # stringsコマンドの特徴量をもとにz2kit_find_strings_by_virustotal.pyとの結果を比較 # Usage: ./z2kit_find_strings_match.py import glob import json import sys import z2kit.elf import z2kit.features import ssdeep def set_features(elffile): if not isinstance(elffile, z2kit.elf.ELFFile): raise ValueError('ELFFile クラスを与えなければなりません。') elffile.features = {} #elffile.features['md5'] = z2kit.features.MD5Feature().get_feature(elffile) #elffile.features['ssdeep'] = z2kit.features.SsdeepFeature().get_feature(elffile) elffile.features['lstrfuzzy'] = z2kit.features.LstrfuzzyFeature().get_feature(elffile) elffile.features['strings'] = z2kit.features.StringsFeature().get_feature(elffile) def is_strings_matching(elffile, substring): for k in elffile.features['strings'].keys(): if substring in k: return True return False def is_malware_to_focus(elffile): return is_strings_matching(elffile, '特徴量として選出した文字列') for filename in glob.glob('z2/VirusShare_*'): try: elffile = z2kit.elf.ELFFile.read_from_file(filename) set_features(elffile) if is_malware_to_focus(elffile): print(filename) except: pass |
著者:しょっさん
インターネットを介する各種サービス、ゲーム、そしてコミュニケーションツールなどの多くが「Webアプリ」として提供されています。このようにWebアプリが普及したのは、プログラミング言語「JavaScript」のおかげです。JavaScriptはフロントエンド開発が中心でしたが、サーバーサイドの実行環境「Node.js」の登場によりバンクエンドのアプリ開発にも使われています。本特集ではNode.js、フレームワークとなる「Express」について、実践しながら分かりやすく紹介します。
記事本文掲載のシェルスクリプトマガジンvol.54は以下のリンク先でご購入できます。
![]()
![]()
|
1 2 3 4 5 6 7 |
const http = require('http'); http.createServer(function (req, res) { res.writeHead(200, { 'Content-Type': 'text/plain' }); res.end('Hello World!'); }).listen(5000); |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
const http = require('http'); const url = require('url'); const port = 5000; const server = http.createServer(); server.on('request', function (req, res) { const uri = url.parse(req.url, true).pathname; const query = url.parse(req.url, true).query; let status = 200; let message = ''; // URIごとに表示するメッセージを変える switch (uri) { case '/': message = 'Hello World!'; break; case '/about': message = 'About page'; break; case '/query': message = 'query: ' + query.name; break; default: status = 404; message = 'Page not found.'; } // http ステータスコードや、実際のメッセージ表示はここ res.writeHead(status, { 'Content-Type': 'text/plain' }); res.write(message); res.end(); }); server.listen(port); |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
// Express の利用宣言 const express = require('express'); const app = express(); const port = 5000; // URIごとの表示メッセージを定義 app.get('/', (req, res) => res.send('Hello World!')); app.get('/about', (req, res) => res.send('About Page')); app.get('/query', (req, res) => res.send('query: ' + req.query.name)); // 指定したポートでサーバーへの受付を開始 app.listen(port); |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
// Expressの利用宣言 const express = require('express'); const app = express(); // URIごとの表示メッセージを定義 app.get('/', (req, res) => res.send('Hello World!')); app.get('/about', (req, res) => res.send('About Page')); app.get('/query', (req, res) => res.send('query: ' + req.query.name)); // 404 not found 1app.use((req, res) => res.status(404).send("Page not found")); // 指定したポートでサーバーへの受付を開始 app.listen(process.env.PORT); // 環境変数 PORTを見るように変更 |
2018年に学ぶべきプログラミング言語として注目の「JavaScript」。特集1では、Webサーバーのバックエンドで動作するJavaScript実行環境「Node.js」と、Node.js向けフレームワークの「Express」を、導入方法も含めて分かりやすく紹介します。ITインフラやIoT(モノのインターネット)の技術者は必見です。
特集2では、すぐに使えるシェルスクリプト/ワンライナー集を紹介します。それぞれのシェルスクリプトやワンライナーで記述しているコードを詳しく解説しています。そのまま使ったり、自分なりにカスタマイズしたりと、自由に活用してください。
特集3では、仮想化技術の一つであるコンテナーの運用管理や運用自動化で定番になりつつある「Kubernetes」(クーバネイティス)を解説します。米Google社のクラウドサービス「Google Cloud Platform」を利用して、Kubernetesの実践的な使い方も紹介します。
特別企画では、一般販売も開始したスマートスピーカー「Amazon Echo」をカスタマイズするための「Alexaカスタムスキル」開発を紹介します。自分だけのAmazon Echoを手に入れましょう。
このほか、好評連載の「ラズパイ入門ボードで学ぶ電子回路の制御」では光センサーを扱います。シェルスクリプトマガジン特製の「ラズパイ入門ボード」を活用してください。
今月も読み応え十分のシェルスクリプトマガジン Vol.54。お見逃しなく!

シェルスクリプトマガジンvol.54のWeb掲載部分まとめです。
シェルスクリプトマガジンvol.54は以下リンク先でご購入できます。
![]()
![]()
04 レポート Ubuntu最新版18.04 LTSが登場 FoundationDBのオープンソース化
06 NEWS FLASH
08 特集1 Node.js/Express入門/しょっさん コード掲載
29 縁の木、育てよう/白羽玲子
30 特集2 シェルスクリプトスニペット集/今泉光之 コード掲載
41 姐のNOGYO
42 特集3 Kubernetesを知る/福田潔 コード掲載
52 特別企画 Alexaカスタムスキル開発入門/岡本秀高 コード掲載
60 ラズパイ入門ボードで学ぶ電子回路の制御/米田聡 コード掲載
64 スズラボ通信/すずきひろのぶ
72 アジャイル開発 Let’s Practice!/熊野憲辰
76 円滑コミュニケーションが世界を救う! /濱口誠一
78 中小企業手作りIT化奮戦記/菅雄一
84 RESEARCHES FOR FUTURE/伊藤貴之
86 香川大学SLPからお届け! /楠目幹 コード掲載
92 法林浩之のFIGHTING TALKS/法林浩之
94 それプロのエバンジェリストから愛をこめて/山本美穂
98 人間とコンピュータの可能性/大岩元
100 バーティカルバーの極意/飯尾淳 コード掲載
106 雲/桑原滝弥・イケヤシロウ
108 漢のUNIX/後藤大地 コード掲載
116 ユニケージ新コードレビュー/大内智明 コード掲載
120 Techパズル/gori.sh
122 コラム「人間がボトルネックになる時代」/シェル魔人
著者:飯尾 淳
前回は、政府統計の総合窓口「e-Stat1」から入手できるデータをダウンロードして、八王子市の町・丁目を示す境界データを地図上に可視化する準備をしました。今回は、実際に地図データを活用できるように、データをきれいに整理する作業を実施します。データをきれいにする作業、それを「クレンジング」と呼びます。
記事本文掲載のシェルスクリプトマガジンvol.54は以下のリンク先でご購入できます。
![]()
![]()
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 |
#!/usr/bin/env python from math import sqrt # 近傍にあるかどうかの判定 def near(a, b, e): (c_ax, c_ay, c_az) = a.split(",") (c_bx, c_by, c_bz) = b.split(",") dx = float(c_ax) - float(c_bx) dy = float(c_ay) - float(c_by) d = sqrt(dx*dx + dy*dy) return (d < e) def splitBorderParts(c0, c1): # 境界面を形作る地点の集合を作成 s0 = [a for a in c0 for b in c1 if near(a, b, 0.00001)] s1 = [b for b in c1 for a in c0 if near(a, b, 0.00001)] # 交差部分がないとき if len(s0) == 0: raise NameError("No intersections!") # 始点が境界面の端に来るように回す if c0[0] not in s0: # 始点が境界面の外にあるとき while c0[0] not in s0: c0.append(c0.pop(0)) else: # 始点が境界面の中にあるとき while c0[-1] in s0: c0.insert(0, c0.pop()) if c1[0] not in s1: while c1[0] not in s1: c1.append(c1.pop(0)) else: while c1[-1] in s1: c1.insert(0, c1.pop()) # 境界面部分を取り出す(元データの境界面には'0,0,0'でマークしておく) i = 0; s0_ = [] for c in c0: if c in s0: s0_.append(c0[i]); c0[i] = '0,0,0' i += 1 i = 0; s1_ = [] for c in c1: if c in s1: s1_.append(c1[i]); c1[i] = '0,0,0' i += 1 return (c0,s0_,c1,s1_) from bs4 import BeautifulSoup import re import sys xml = open("./sample4.kml") bsObj = BeautifulSoup(xml.read(), "lxml") targets = bsObj.findAll("coordinates") coords = [] for coord in targets: val = re.sub(" +", "", coord.get_text()).split("\n") while val.count(""): val.remove("") # 先頭と末尾が重複しているので,とりあえず先頭を削除 val.pop(0) coords.append(val) try: # 第1引数で与える配列の非境界面(c0), 境界面(s0), # 第2引数で与える配列の非境界面(c1), 境界面(s0) を求める (c0,s0,c1,s1) = splitBorderParts(coords[0], coords[1]) # c0とc1から'0.0.0'を取り除く while c0[0] == '0,0,0': c0.pop(0) while c1[0] == '0,0,0': c1.pop(0) # c0,c1の頭にs0,s1の末尾(境界面の端点)を追加 c0.insert(0, s0[-1]) c1.insert(0, s1[-1]) # c0とc1を繋いで出力(最後に先頭を出力して閉領域完成) print (“<coordinates>”) for f in c0: print (“ ”, f) for f in c1: print (“ ”, f) print (“ ”, c0[0]) print (“</coordinates>”) except NameError: sys.exit() |
著者:福田 潔
コンテナー型の仮想化環境を提供するソフトウエア「Docker」の普及により、その運用管理が重要になってきています。Kubernetesは、最も注目されているコンテナー運用管理/運用自動化ツールです。本特集では使い方も含めて、Kubernetesについて分かりやすく紹介します。
記事本文掲載のシェルスクリプトマガジンvol.54は以下のリンク先でご購入できます。
![]()
![]()
|
1 2 3 4 5 6 7 8 |
apiVersion: extensions/v1beta1 kind: Ingress metadata: name: basic-ingress spec: backend: serviceName: web servicePort: 8080 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
apiVersion: extensions/v1beta1 kind: Ingress metadata: name: basic-ingress spec: rules: - http: paths: - path: /* backend: serviceName: hello-server servicePort: 8080 - path: /v2/* backend: serviceName: hello-server2 servicePort: 8080 |
著者:今泉 光之
日々の業務でよく使い回すちょっとしたコードの羅列を「スニペット」(断片)として用意しておくと便利です。本特集では、作業の自動化に便利であろういくつかのシェルスクリプトスニペットを紹介します。
記事本文掲載のシェルスクリプトマガジンvol.54は以下のリンク先でご購入できます。
![]()
![]()
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
#!/bin/sh # SSL証明書の有効期限をチェックして管理者に通知する # 1日数回の実施 (10:00 / 13:00 / 16:00 / 18:00) を想定している cert="${1}" host=${2:-`hostname`} check=/tmp/sslcheck-send # リミット soft=$((30 * 24 * 60 * 60)) hard=$((10 * 24 * 60 * 60)) # パラメーターチェック if [ -z "${cert}" ] then echo "Usage: $(basename ${0}) certfile [hostname]" 1>&2 exit 1 fi # 証明書から有効日を取得 limit=$(date -d "$(openssl x509 -noout -text -in ${cert} | sed -n '/Not After/s/.* : ¥(.*¥).*/¥1/p')" '+%Y/%m/%d %H:%M:%S') limit_s=$(date -d "${limit}" '+%s') today=$(date -d "00:00:00" '+%Y/%m/%d %H:%M:%S') today_s=$(date -d "${today}" '+%s') current_s=$((${limit_s} - ${today_s})) current=$((current_s / (24 * 60 * 60))) if [ ${current_s} -lt 0 ] then # 証明書期限切れ notice "ホスト ${host}の SSL証明書の期限が ${limit}で終了しています。大至急更新作業をして下さい。" elif [ ${current_s} -le ${hard} ] then # 証明書期限まで残り 10 日以内 notice "ホスト ${host}の SSL証明書の期限が ${limit}までです (残り ${current}日 )。至急更新作業をして下さい。" elif [ ${current_s} -le ${soft} ] then # 証明書期限まで残り 30 日以内 (1日 1回通知 ) update=$(date '+%m%d') if ! [ -f ${check} -a "$(cat ${check})" -eq ${update} ] then notice "ホスト ${host}の SSL証明書の期限が ${limit}まです (残り ${current}日 )。更新作業をして下さい。" echo ${update} > ${check} fi fi |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
#!/bin/sh target="https://hooks.slack.com/services/XXXXXXXXX/XXXXXXXXX/XXXXXXXXXXXXXXXXXXXXXXXX" icon="表示されるアイコン " name="表示される名前" exec > /dev/null 2>&1 notice() { curl -X POST -H 'Content-type: application/json' --data '{"text": "'"${*}"'", "icon_emoji": "${icon}", "username": "${name}" }' ${target} } |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
#!/bin/sh tmpfile=${TMP:-/tmp}/rdf.$$ ssh="/usr/bin/ssh" df="LANG=C df -hlP -t ext3 -t ext4" servers="サーバー 1 サーバー 2 … サーバー n" trap 'rm -rf ${tmpfile}; exit' 0 1 2 3 15 for i in ${servers} do ${ssh} ${i} ${df} | tee ${tmpfile} | awk '{ if(NR > 1) ret += $(NF-1) > '${1:-80}' } END{ exit ret; }' || notice "${i} DISK Usage Warning!¥n $(cat ${tmpfile})" done |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
#!/bin/sh usage() { echo "Usage: $(basename $0) [-f][-l time] process" 1>&2 exit 255 } # パラメーターチェック if opt=`getopt fl: $*` then set -- ${opt} while [ -n "${1}" ] do case "${1}" in -f ) cmd="sh";; -l ) limit=$2 shift;; -- ) shift break;; -* ) usage;; esac shift done else usage; fi test $# -ne 1 && usage ps ax | awk -v "process=${1}" -v "limit=${limit:-100}" ' { if($5 ~ process) { gsub(/:/, "", $4); if(($4 + 0) > (limit * 100)) pid = pid " " $1 } } END{ if(pid) print "kill" pid }' | ${cmd:-cat} |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
#!/bin/sh source="${1}" target="$(pwd)/${2}" if true then doit() { nkf -e ${1} > ${2} } else doit() { local _wav wav=$(echo "${2}" | sed 's/m4a/wav/') faad -q "${1}" -o "${wav}" lame --quiet -h -b 192 "${wav}" "${2}" rm "${wav}" } fi cd ${source} || exit 1 find . | while read line do if [ -d "${line}" ] then mkdir -p "${target}/${line}" else doit ${line} ${target}/${line} fi done |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
#!/bin/sh # バックアップ対象はホスト名を大文字にした名前でマークする # ホスト名が myhost.example.comの場合 "MYHOST"でマーク # ディレクトリー /some/directoryをバックアップする場合 /some/directory.MYHOSTを touchする # ファイル /some/fileをバックアップする場合 /some.file.MYHOSTをtouchする # ファイルを /some/fileを編集するときにオリジナルを /some/file.MYHOST にコピーしておくと # バックアップ対象になり、更に変更内容を diffなどで変更内容を容易に確認できる。 # max generation(s) max=7 # files and directories backupdir=/home/backup targetdir=${backupdir}/$(date '+%Y%m%d') latestdir=${backupdir}/latest # backup target base=$(hostname -s | tr [:lower:] [:upper:]) # prepare directories test -d ${backupdir} && test $(ls -1 ${backupdir} | wc -l) -ge ${max} && rm -rf ${backupdir}/$(ls -1 ${backupdir} | head -1) mkdir -p ${targetdir} rm -rf ${latestdir} ln -s ${targetdir} ${latestdir} find / -name "*.${base}" | sed "s!^/¥(.*¥)¥.${base}$!¥1!g" | tar -C / -cvzf ${targetdir}/${base}.tgz -T - |
|
1 |
top bn1 | sed -n -e '1,/^$/p' -e '/apache/p' |
|
1 |
ps axH | awk '/[a]pache/{ $4=""; print $0} ' | sort -k 1,1 -rn | uniq -c |
|
1 |
awk '{ if($7!="408"){sub(/?.*/, "", $7); u[$7]++} }END{ for(key in u) print u[key], key }' access.log | sort -nr |
|
1 |
awk '{ c[$1]++ }END{ for(key in c) print c[key], key }' access.log | sort -nr |
著者:岡本 秀高
2018 年3 月30 日、スマートスピーカー「Amazon Echo」の一般販売が開始されました。そのバックエンドに使用されるAIアシスタント「Amazon Alexa」を活用することで、自分のオリジナルアプリ(スキル)を簡単に作成できます。本企画で、シンプルなスキルを作りながら、スキルの開発方法を学んでいきましょう。
記事本文掲載のシェルスクリプトマガジンvol.54は以下のリンク先でご購入できます。
![]()
![]()
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 |
'use strict'; // alexa-sdkを取得 const Alexa = require('alexa-sdk'); // AlexaのスキルIDを指定(省略可) const APP_ID = ''; // リクエスト内容から、nameスロットの値を取り出す処理 const getName = (event) => { if (!event.request.intent) return ''; if (!event.request.intent.slots.name.value) return ''; return `${event.request.intent.slots.name.value} さん`; } // インテントごとのレスポンスをオブジェクト形式で定義 // キーがインテント名となる const handlers = { 'LaunchRequest': function () { // LaunchRequestでは、HelloIntentを同じ内容を話すように設定 this.emit('HelloIntent'); }, 'HelloIntent': function () { const name = getName(this.event); // ユーザーからの返答が必要ない場合は「:tell」を使う // 第2引数にAlexaにしゃべらせたい内容を記述 this.emit(':tell', 'アレクサスキルへようこそ。' + name); }, 'Unhandled': function () { // Unhandledはユーザーの発話内容がどのインテントにも一致しなかった場合に呼び出される // ユーザーからの返答を求めたい場合は「:ask」を使う // 第2引数にAlexaにしゃべらせたい内容を記述 // 第3引数にユーザーがしばらく返答しなかった場合に再度よびかける内容を記述 this.emit(':ask', 'すみません。よく聞き取れませんでした。なにか試したいことはありますか?', 'なにか試したいことはありますか?'); }, 'AMAZON.HelpIntent': function () { // AMAZON.XXXIntentはAmazonのビルトインインテント // ビルトインインテントの詳細:https://developer.amazon.com/ja/docs/custom-skills/implement-the-built-in-intents.html this.emit(':ask', 'これはアレクサのサンプルスキルです', 'なにか試したいことはありますか?'); }, 'AMAZON.CancelIntent': function () { this.emit(':tell', 'ごきげんよう。'); }, 'AMAZON.StopIntent': function () { this.emit(':tell', 'ごきげんよう。'); }, }; // Alexaからのリクエストはeventに含まれる exports.handler = function (event, context, callback) { // alexa-sdkをセットアップ const alexa = Alexa.handler(event, context, callback); // AlexaのスキルIDをここで定義 alexa.appId = APP_ID; // 作成したレスポンスを登録 alexa.registerHandlers(handlers); // execute()を実行することで、リクエストに対応したレスポンス返す alexa.execute(); }; |
2018年4月26日に「Ubuntu 18.04 LTS」がリリースされました(図1)。今まで連載で紹介してきた「Ubuntu 16.04 LTS」に代わる長期サポート版(LTS)です。Ubuntu 18.04 LTSでは、カーネルを含む多くのソフトウエアが更新されました。

図1 Ubuntu 18.04 LTSのリリースノート(https://wiki.ubuntu.com/BionicBeaver/ReleaseNotes)
サーバー版の「Ubuntu Server 18.04 LTS」では、ネットワークユーティリティーとして「NetPlan」が採用され、ネットワーク設定は「systemd-networkd」というデーモンで管理されています。また、デフォルトのインストーラーが「Subiquity」となり、九つのステップで簡単にインストール可能になりました。
今回は、このUbuntu Server 18.04 LTSをSubiquityでインストールする方法と、ストレージを柔軟に管理する仕組み「LVM」(Logical Volume Manager)を設定したインストール方法を紹介します。Subiquityでは、インストールが簡単になった分、LVMが設定できません。
shell-mag ブログの 2018年5月 のアーカイブを表示しています。