written by シェルスクリプトマガジン編集部

この記事は、シェルマガvol.48掲載「バーティカルバーの極意」第二回の、いわゆる「やってみた記事」です。
シェルマガ本誌と一緒にご覧頂けると、よりお楽しみいただけます。
![]()
![]()
はじめに
よちよち歩きで運用を開始した、Web版シェルスクリプトマガジン shell-mag.com 。
更新のたびにFacebookやTwitterなどのSNSに投稿をしてお知らせしていますが、当然お知らせがどれだけの人に届いたか、気になるものです。
たとえばこちらの投稿。

「さて、この投稿のリーチ(投稿が見られた数)は……ええー、たったの70?(しょんぼり)」
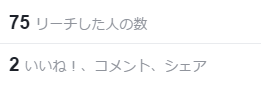
たとえばFacebookでは、これまでにリーチが1000近くまで伸びた投稿もあるので、100以下はちょっと堪えます。
まだまだ記事数こそ少ないですが、面白おかしく役に立つ記事を揃えていると自負していますから、せっかく更新した記事が人の目にも触れないと、こちらとしては面白くありません。
なんとかFBでもリーチ数を稼がねば。
Facebookのアルゴリズムではリアクションが多くついた投稿ほど頻繁に表示されるらしいので、リーチを伸ばす正攻法は、まずはキャッチーな、「いいね」をもらいやすい投稿をすることです。
とはいえ、「いいね」をもらえるかどうかはなかなか水物です。なんとか確実にリーチ数を稼ぐ方法はないものか。
そこで、わたくし考えました。
シェルマガの読者さんは皆さま品行方正でしょうから、わたくし編集Kみたいに昼間からSNSに入り浸ったりはせずに、仕事に疲れ、傷つき、リラックスしたい時間だけSNSにアクセスしているはず。
だとすれば、多くの人が休憩をとる、リーチが伸びやすい時間帯があるはずです。
その時間を狙って更新情報を投稿するように心がければ
→自動的にshell-mag.comの利用が増える
→満足した読者さんの口コミでサイトの知名度が上がる
→シェルマガ本誌も売上が伸びる
→編集Kの給料も上がる
と、おお、これはいいことづくめだ!すぐにでも解析をせねば。
……と考えていたところに、前号から始まった、飯尾淳先生による「バーティカルバーの極意」第2回の原稿が届きます。早速確認してみると、おあつらえ向きに「Facebookの投稿をヒストグラムで分析する」内容ではないですか。
「これは使えるぞ!」と、ピーンと来た編集K。
記事のコードチェックも兼ねて、Facebookへの投稿の解析を試みることにしたのでした。
シェルマガvol.48に掲載された「バーティカルバーの極意」第二回では、どの時間帯に飯尾先生がFacebookに投稿しているのか、ヒストグラムで可視化をしていましたが、私の目的である「どの時間帯に投稿すればリーチが伸びるのか」を分析するためには、ヒストグラムよりも散布図のほうが役に立つはずです。
理想的には、例えば下の図のように、「昼休みに入る12時前後と定時の18時前後の投稿は、他の時間帯に比べてリーチ数が伸びやすい」のような傾向が見て取れるはず。
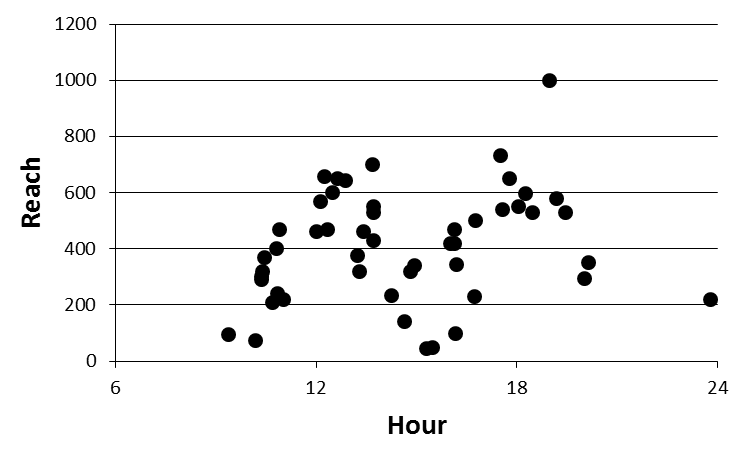
(Excelでちまちまつくりました)
善は急げ。早速Facebookからデータを取得して、解析してみましょう!
苦闘の記録
手元には飯尾先生のお手本があるから、今回の解析は簡単にできるはず……との目論見は、初っ端から崩れます。ビジネスアカウントでは、投稿情報の取得の際に、なんと28日しか遡れないのです。その間の投稿数は10程度。とても、議論ができるサンプル数ではありません。

しょうがないので、投稿日時とリーチ数が表示されるページから、マウスで選択してコピペする原始的な方法でテキストデータを引っ張ってきます。
原始的な方法でデータを取得するの図。ビーッと引っ張ってきます。
さて、取得したデータをテキストにペーストしてみると……
……あれ?
飯尾先生の記事では「データがすべて横に並んでいたので改行コードを挿入して扱いやすいデータにする」というストーリーでしたが、私が取得したデータは、逆にすべて縦に並んでいます。これは困ったなぁ。
困ったときは相談だ。というわけで、隣の席のエンジニアに助け舟を出してもらいます。
編集K「ねぇねぇ、この全部縦に連なったデータを、常識的な並び方に直すにはどうしたらいいかねぇ」
エンジニア「そりゃ、一度全部横にしてから、適当な改行コードを入れるしかないでしょ(編:だよねぇ~)。そういうときはyarrコマンドを使ったらいいんだよ」
yarr(横アレイ)!!ここでまさかのTukubaiコマンド登場です。そりゃまぁ、Tukubaiコマンドを使っていかに楽をしてシステムを組み立てるかを日夜考えている、うちのエンジニアに聞いたら当然そういう答えが返ってきますよね。
注:Tukubaiコマンドは、シェルマガの発行元USP研究所が開発しているUNIXコマンド群。シェルマガ著者の今泉光之さん曰く「便利すぎて考えなくて済むから、エンジニアが馬鹿になる」とのこと。個人用Tukubaiのご購入はこちら。
オーケーオーケー。他のサイトならまだしも、ここはshell-mag.com 。ユニケージの広報サイトでユニケージのために開発されたコマンドを使って何が悪い。ちょっとズルいですが、Tukubaiコマンドを使っちゃいましょう。
yarrは、縦に並んだデータを横に並び替えるコマンドです。こんなこともあろうかと優しい誰かが作ってくれていたのでしょう。
sedで半角スペースを適当な文字列に変換してから、yarrコマンドでデータの縦横を入れ替えます。
|
1 |
$ sed ‘s/ /_/g’ FBdata.txt | yarr > FBdata2.txt |
2017年5月31日追記:飯尾先生から「標準的なコマンドだけでも、pasteを使えば同じことができるよ」とご指摘をいただきました。yarrをpasteに置き換え、以下のようにオプションを使えば同じ出力が得られます。
|
1 |
$ sed ‘s/ /_/g’ FBdata.txt | paste -d ' ' -s - > FBdata2.txt |
で、こいつをcatで開いてみると……
あれ、縦のまんまだ?どういうことよ。(注:pasteコマンドを使っても結果は同じです)
Vimで開いてみると
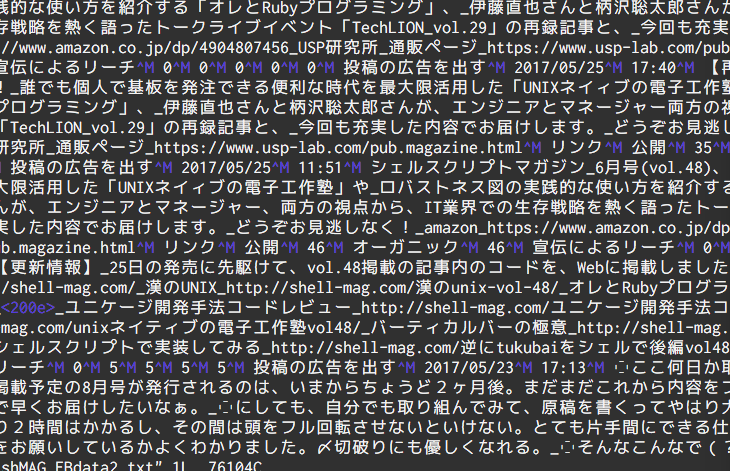
おお、紫でハイライトされている^Mの改行コードが残っているんですな。こいつもsedで取ってやりましょう。
|
1 |
$ sed ‘s/^M//g’ FBdata2.txt > FBdata3.txt |
ただし、この制御コードの^Mは、素直に「はっと・えむ」とキーを打ってもsedで認識してくれません。キー入力としては、Ctrl-v Ctrl-mと入力すると制御コードの^Mと認識されるので、入力の際には
|
1 |
$ sed ‘s/ Ctrl-v Ctrl-m //g’ FBdata2.txt > FBdata3.txt |
とタイプしてください。さらっと流しましたが、これを調べるのに20分かかりました。
さて、無事にデータが横一行に並んだので、飯尾先生の教えの通り、sedを使って特定のテキストを改行コードに置き換え、データを扱いやすい形に整えます。今回は、各投稿の最後に「投稿の広告を出す」という一文が必ず入っているので、これを改行コードに書き換えました。
|
1 2 |
$ LF=$'\\\x0A' $ cat timeline.htm | sed -e 's/"投稿の広告を出す"/'"${LF}"'/g' > FBdata4.txt |
ここもさらっと流していますが、編集Kの使っているMacのOSのバージョンが古かったのか、改行コードを改行コードとして認識してもらえませんでした。再度隣席のエンジニアに頼み、彼のMacで同じコマンドを打ってもらったところ、想定通り改行されましたので、読者の皆さまは安心して記事のコードを使ってください。
さて、こうやって加工したデータですが、まだ行頭に空白があったり、最終行に空行が入っていたりと、まだ形を整える必要があります。AWKとかを使うのがめんどくさいので、再度Tukubaiコマンドを使って加工します。末尾の行を削って、余分な空白をとって、日付と時間とリーチのフィールドを取り出します。
|
1 |
$ cat FBdata4.txt | ctail 1 | self 1/N | self 1 2 8 > FBdata5.txt |
ctail :ファイルの末尾指定行を削って出力
self : 指定したフィールドのデータを取り出す。連続した空白をひとつに削ることができる。
こうやって、弊社のプロダクトを自然にステマしながら加工したデータがこちらになります。
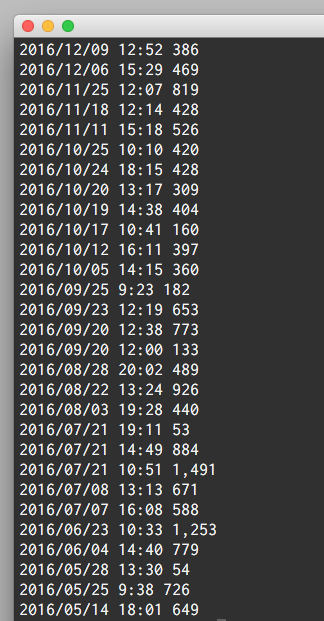
おお、綺麗になった。でもリーチ(第3フィールド)に3桁ごとのカンマが残ってますね。これもsedで消してしまいましょう。ついでにhourとminuteの間のコロンを空白に変えて、それぞれを独立したフィールドにしてしまいます。で、minuteの方を60進法から10進法に直して、hourと合計を出します。
|
1 |
$ cat FBdata5.txt | sed –e ‘s/,//g’ | sed –e ‘s/:/ /g’ | awk ‘{print $2+($3)/60,$4}’ > FBdata6.txt |
これで、プロットする元データが加工できました。第1フィールドが時刻、第2フィールドがリーチ数です。
さて、元記事に倣って、これをRでグラフにしてみます。
|
1 |
$ R -q -e 'x<-read.table("/user/FBdata6.txt", header=F); plot(x$V1,x$V2, xlim =c(6, 24), ylim = c(0, 1000), xlab = "Time", ylab = "Reach")' |
飯尾先生の記事ではhist関数を使っていますが、今回つくるのはヒストグラムではなく散布図なので、plot関数を使います。最初に横軸と縦軸を指定します。$V1、$V2は、それぞれ何フィールド目かを表します。小室哲哉とYOSHIKIが組んだユニットではありませんし、宮内洋も出てきません。何の話だ。グラフの範囲をxlim、ylimで指定、xlab、ylabでそれぞれ軸のラベルを指定します。
完成!
で、ここまで3時間ほど苦闘した末、完成した散布図がこちらになります。
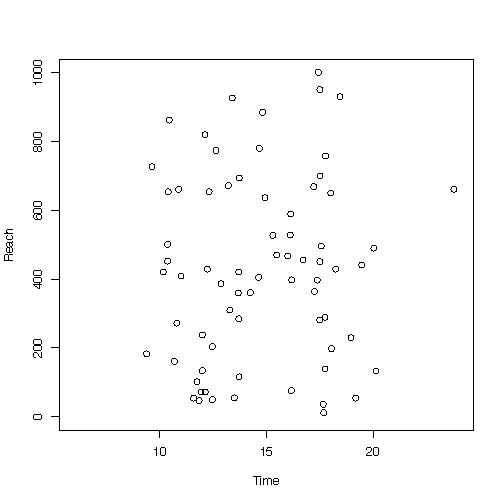
(縦軸がリーチ数、横軸が投稿時刻になります)
お、おう……。
正直、傾向はよくわかりませんな。当初は12時と18時前後に投稿するとリーチが増えるんじゃないかと考えていましたが、別段そんなこともない。強いて言えば、15時頃はリーチが安定して見えますが、これもサンプル数が少なくて確実とはいえんなぁ……。
とりあえずの結論としては
「投稿の時間帯だけでリーチ数をコントロールしようとするのは無理がある」
ということですね。やはり正攻法で、キャッチーな投稿を心がけねば。
というわけで、皆さまもどうぞシェルマガの記事を自分なりに試して楽しんでくださいね!
当サイト掲載のコードもコピペなどにどうぞご利用ください。
今回の記事の元ネタ「バーティカルバーの極意 第二回」のコードはこちら。コピペなどにご利用ください。
解説はシェルマガ本誌をご参照くださいませ。
(次回、「バーティカル・マイスターの遍歴時代」に続く……のか?)











