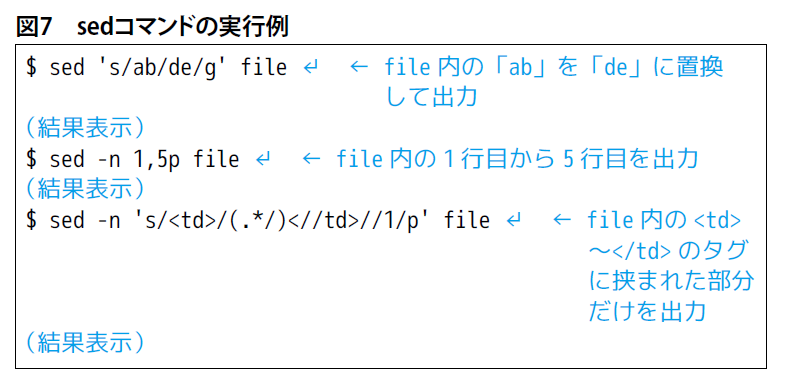
SQLのようなデータ抽出操作
業務システム開発手法の「ユニケージ」では、データベース管理システムやフレームワークなどを使わずにシステムを構築します。システムの中身が見えやすい分、仕組みやルールを理解していないと正しい開発ができません。第3回は、専用コマンドでSQLのSELECT文のようなデータ抽出操作を実施します。
今回は、ユニケージの専用コマンド群「usp Tukubai」を用いて、タグ形式で保存したデータファイルに対し、データベース問い合わせ言語「SQL」のようなデータ抽出の操作を実施します。タグ形式で保存したデータファイルとは、1行目に半角スペースで分けられたデータの項目(タグ名)が並んでいて、2行目以降にその項目ごとに分けられたデータを保存しているテキストファイルです。
SQLのような抽出操作ができるコマンド
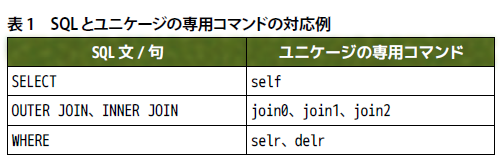
usp Tukubaiには、タグ形式のデータファイルを扱うコマンドが多数用意されています。例えば、「tagself」「tagawk」「tagsort」「tagcond」「tagjoin0」「tagjoin1」「tagjoin2」といったコマンドです。これらのコマンドでは、SQLの「SELECT」(検索)文のようなデータ抽出やデータ結合などの操作が可能です(表1)。このほかにもタグ形式のデータファイルを処理するコマンドは30種類以上あり、条件によって組み合わせて使用できます。

usp Tukubaiに含まれるすべてのコマンドに共通していますが、ファイルに対してコマンドを適用しても、元のファイルを書き換えるわけではありません。コマンドの実行結果は、標準出力に渡され、元のファイルは残っています。このような特徴からSQLの「INSERT」(挿入)文、「DELETE」(削除)文、「UPDATE」(更新)文のような操作をするユニケージ専用コマンドはありません。しかし、シェルのリダイレクトである「>」を使って標準出力の内容をファイルとして出力することによって、INSERT文やDELETE文、UPDATE文、さらにテーブルを作成する「CREATE」文を実現しています。
それでは、先ほどのtagself、tagawk、tagsort、tagcondのコマンドをSQL文と比較しながら紹介します。なお、tagjoin0、tagjoin1、tagjoin2といった、テーブルを結合するコマンドは次回に詳しく解説する予定です。
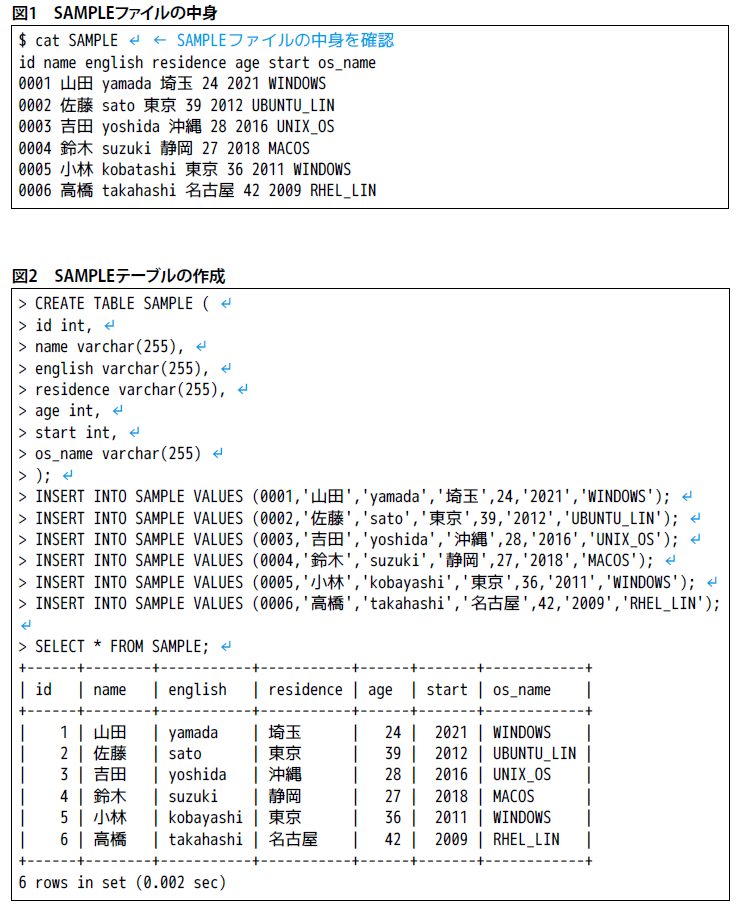
紹介時に用いる元データとして「SAMPLE」ファイル(図1)を用意します。これらのファイルやテーブルには、「id」(社員番号)、「name」(名前)、「english」(英語名)、「residence」(居住地)、「age」(年齢)、「start」(入社年度)、「os_name」(使用パソコン)が書き込まれています。
また、図2のSQLを実行し、MySQLなどのデータベース管理システムにSAMPLEファイルと同じ内容となる「SAMPLE」テーブルを作成します。
指定した項目のデータを抽出
tagselfは、引数に指定した項目のデータを抽出するコマンドです。tagselfコマンドの基本構文は、次のようになります。抽出したい項目(タグ)の名前を半角スペースで区切って並べて、最後にデータファイル名を指定します。
|
1 |
tagself 項目名 項目名… データファイル名 |
例えば、SAMPLEファイルから社員の名前と年齢だけを抽出するなら、
|
1 2 3 4 5 6 7 8 |
$ tagself name age SAMPLE ↵ name age 山田 24 佐藤 39 吉田 28 鈴木 27 小林 36 高橋 42 |
のようにtagselfコマンドを実行します。項目名付きで抽出したデータが表示されます。これは、次のSQLを実行したのと同じ結果です。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
> SELECT name,age FROM SAMPLE; ↵ +--------+------+ | name | age | +--------+------+ | 山田 | 24 | | 佐藤 | 39 | | 吉田 | 28 | | 鈴木 | 27 | | 小林 | 36 | | 高橋 | 42 | +--------+------+ 6 rows in set (0.001 sec) |
条件付きでデータを抽出
SQLのSELECT文には、条件を指定してデータを抽出する「WHERE」句があります。例えば、SQLでSAMPLEデータベースから30歳よりも年齢の高い社員の名前、年齢を抽出するなら、
|
1 2 3 4 5 6 7 8 9 |
> SELECT name,age FROM SAMPLE WHERE age > 30; ↵ +--------+------+ | name | age | +--------+------+ | 佐藤 | 39 | | 小林 | 36 | | 高橋 | 42 | +--------+------+ 3 rows in set (0.001 sec) |
のように実行します。ユニケージで同じような処理を実行するには、次のようにtagawkコマンドで条件を指定します。
|
1 2 3 4 5 |
$ tagawk 'NR == 1{print %name,%age}NR > 1 && %age > 30{print %name,%age}' SAMPLE ↵ name age 佐藤 39 小林 36 高橋 42 |
tagawkコマンドの基本構文は、
|
1 |
tagawk 'パターン{アクション}…' データファイル名 |
になります。パターンやアクションは、プログラミング言語「AWK」のパターンやアクションと同じような記述をします。
パターンの「NR == 1」では1行目という条件、項目名が記されている行(1行目)を示しています。次の「NR > 1 && %age >30」は、2行目以降に対して、age項目が「30」より大きい行といった条件になります。これらの条件に一致したものに対して、それぞれのアクションに記した「print %name,%age」により「%項目名」で指定した名前と年齢のみが表示されます。なお、「%項目名」の指定は、AWKにはなく、tagawkコマンドの独自仕様です。
tagawkコマンドでは、前述したようにAWKを知らないと、パターンやアクションの記述が難しいといえます。また、項目行も意識する必要があります。大小比較のような、複雑なパターンマッチングを必要としない条件であれば、tagcondコマンドが利用できます。
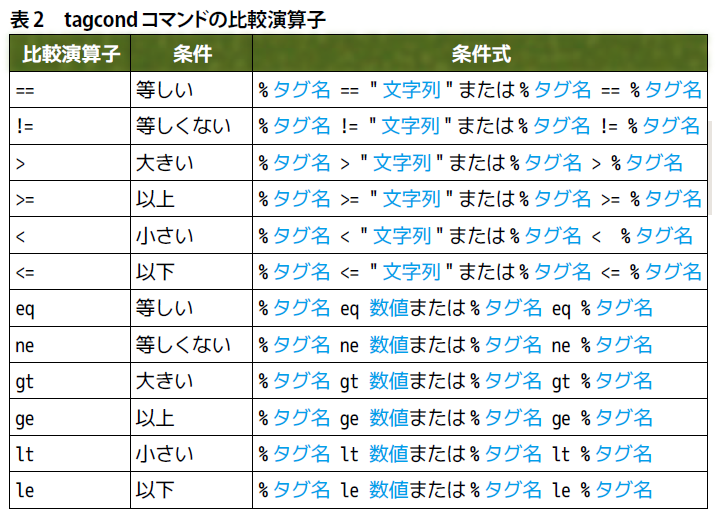
tagcondコマンドの基本構文は、次のようになります。条件式には、表2のような比較演算子が使えます。
|
1 |
tagcond 条件式 データファイル名 |
先ほどのSAMPLEファイルから30歳よりも年齢の高い社員の名前、年齢を抽出するなら、
|
1 |
$ tagcond '%age gt 30' SAMPLE | tagself name,age ↵ |
のように実行します。tagcondコマンドでは、1行目を項目行と判断して2行目以降に条件式を適用します。なお、tagcondコマンドには、項目を絞り込む機能がありません。よって、tagselfコマンドを併用します。
tagcondコマンドは、複雑な条件を必要としない場合に用いると述べましたが、SQLのWHERE句の「AND」や「OR」のように「&&」や「||」を使って複数の条件を組み合わせられます。
例えば、30代の社員の名前、年齢を抽出するなら、次のようにtagcondコマンドを実行します。
|
1 2 |
$ tagcond '%age ge 30 || %age lt 40' SAMPLE | tagself name,age ↵ |
データを並べ替える
SQLのSELECT文には、データを並べ替える「ORDER BY」句があります。例えば、SAMPLEデータベース内の社員名と出身地、社員の英語名を英語名の昇順に並べるなら、
|
1 2 3 4 5 6 7 8 9 10 11 12 |
> SELECT name,residence,english FROM SAMPLE ORDER BY english; ↵ +--------+-----------+-----------+ | name | residence | english | +--------+-----------+-----------+ | 小林 | 東京 | kobayashi | | 佐藤 | 東京 | sato | | 鈴木 | 静岡 | suzuki | | 高橋 | 名古屋 | takahashi | | 山田 | 埼玉 | yamada | | 吉田 | 沖縄 | yoshida | +--------+-----------+-----------+ 6 rows in set (0.001 sec) |
のように実行します。ユニケージで同じ処理を実行するには、次のようにtagmsortコマンドとtagselfコマンドを使います。
|
1 2 3 4 5 6 7 8 |
$ tagmsort key=english SAMPLE | tagself name residence english ↵ name residence english 小林 東京 kobayashi 佐藤 東京 sato 鈴木 静岡 suzuki 高橋 名古屋 takahashi 山田 埼玉 yamada 吉田 沖縄 yoshida |
「key=項目名」には、並べ替える対象とする項目を記載します。データファイルの1行目は、項目行だと認識されて、2行目以降の並べ替えが実施されます。tagcondコマンドと同様に、tagmsortコマンドには、出力項目を絞り込む機能はないのでtagselfコマンドを併用します。
tagmsortコマンドは、並べ替えのアルゴリズムとして「マージソート」を利用しています。また、ユニケージでは大量データの高速な並べ替え処理も必要とされているため、すべてのデータをメモリー上に読み込んでからソート処理を実施しています。
tagmsortコマンドでは、文字列(文字コード)による昇順の並べ替えがデフォルトです。ただし、ORDER BY句の「ASC」(昇順)や「DESC」(降順)のような並べ替えも可能です。具体的には、文字列による降順なら項目名の後に「:r」を、数値による昇順なら「:n」を、数値による降順なら「:N」を付与します。
例えば、入社年度の降順で社員名と出身地、入社年度を並べ替えるなら、SQLでは、
|
1 2 3 4 5 6 7 8 9 10 11 12 |
> SELECT name,residence,start FROM SAMPLE ORDER BY start DESC; ↵ +--------+-----------+-------+ | name | residence | start | +--------+-----------+-------+ | 山田 | 埼玉 | 2021 | | 鈴木 | 静岡 | 2018 | | 吉田 | 沖縄 | 2016 | | 佐藤 | 東京 | 2012 | | 小林 | 東京 | 2011 | | 高橋 | 名古屋 | 2009 | +--------+-----------+-------+ 6 rows in set (0.001 sec) |
のように実行します。ユニケージなら次のようにtagmsortコマンドとtagselfコマンドを実行します。
|
1 2 3 4 5 6 7 8 |
$ tagmsort key=start:N SAMPLE | tagself name residence start ↵ name residence start 山田 埼玉 2021 鈴木 静岡 2018 吉田 沖縄 2016 佐藤 東京 2012 小林 東京 2011 高橋 名古屋 2009 |
tagmsortコマンドでは、複数の条件での並べ替えも実施できます。「key=項目名」の後に「@」を付けて項目名を並べます。
文字列の一致によるデータ抽出
SQLのSELECT文には、指定した文字列に一致したデータを抽出するための「LIKE」句があります。例えば、SAMPLEデータベース内の使用パソコンで「LIN」が末尾に付くLinux OSを使用している、社員名、年齢、使用パソコンを調べるには、
|
1 2 3 4 5 6 7 8 9 |
> SELECT name,age,os_name FROM SAMPLE WHERE os_name LIKE '%LIN'; ↵ +--------+------+------------+ | name | age | os_name | +--------+------+------------+ | 佐藤 | 39 | UBUNTU_LIN | +--------+------+------------+ | 高橋 | 42 | RHEL_LIN | +--------+------+------------+ 2 row in set (0.001 sec) |
のように実行します。LIKE句では正規表現が使え、「%」が0文字以上の任意の文字列、「_」が任意の1文字に対応します。
LIKE句と同様の処理を、ユニケージでは条件検索で登場したtagcondコマンドで実行できます。次のように条件式に正規表現を使って記述します。
|
1 |
tagcond '%項目名 ~ /正規表現/' データファイル名 |
先ほどのSQLをtagcondコマンドで書き換えると、次のようになります。
|
1 2 3 4 |
$ tagcond '%{os_name} ~ /LIN$/' SAMPLE | tagself name age os_name ↵ name age os_name 佐藤 39 UBUNTU_LIN 高橋 42 RHEL_LIN |
「$」が行末を表す正規表現です。ちなみに、行頭は「^」、任意の1文字は「.」で表します。
今回は、SQLのSELECT文をユニケージの専用コマンドで表してみました。次回は、今回紹介した以外の演算子、「IN」や「HAVING」、テーブル結合の「JOIN」などの句をユニケージ専用コマンドで表現する方法を解説します。
著者:田渕 智也、高橋 未来哉
※本記事は、シェルスクリプトマガジン Vol.83(2023年4月号)に掲載した記事からの転載です。