一般のデータベースとの違い
業務システム開発手法の「ユニケージ」では、データベース管理システムやフレームワークなどを使わずにシステムを構築します。システムの中身が見えやすい分、仕組みやルールを理解していないと正しい開発ができません。最終回は、一般のデータベース管理システムと、ユニケージのデータベースとの違いを紹介します。
一般的なデータベース管理システムと、ユニケージのファイルによるデータベースには「汎用型」と「業務特化型」という大きな違いがあります。
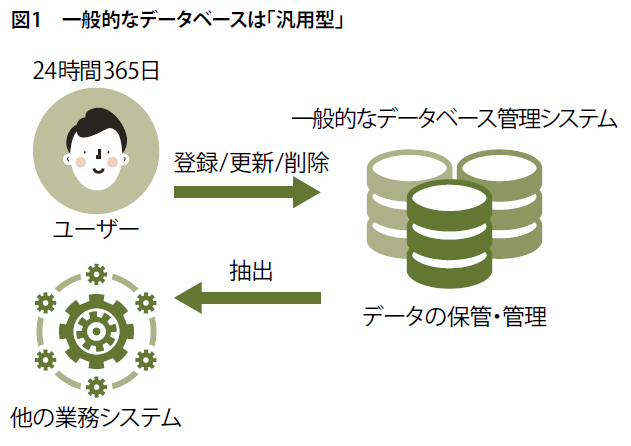
一般的なデータベース管理システムは、24時間365日どのようなアクセスがあってもデータの保管と管理ができなくてはいけません(図1)。そのため、汎用型と呼べるでしょう。
一方、ユニケージのデータベースは、業務というルールを基にしてデータの保管と管理が可能であればよいといえます。例えば、伝票処理なら平日8時~17時までの登録と参照ができればよいでしょう(図2上)。他のシステムからのデータ集計なら業務終了後の20時過ぎからデータの集計・保管を開始すればよいわけです(図2下)。このようにルールに即したデータの保管と管理なら、必要がない機能を省いて最適化が比較的容易です。
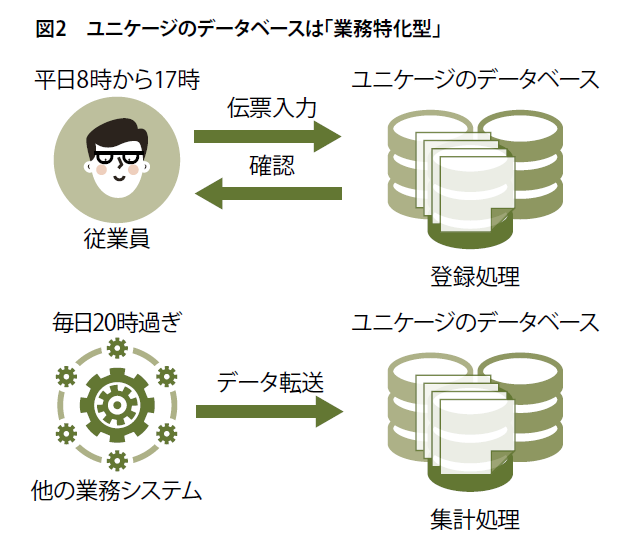
ユニケージのデータベースは業務特化型です。特に、ユニケージのデータベースには業務システムで得た長年のノウハウがいろいろと盛り込まれています。
五つのレベルで管理
ユニケージのデータベースでは、一般的なデータベース管理システムのようにマスターのテーブルだけにデータを蓄積しているわけではありません。L1~L5という五つのレベルでデータを管理しています(図3)。
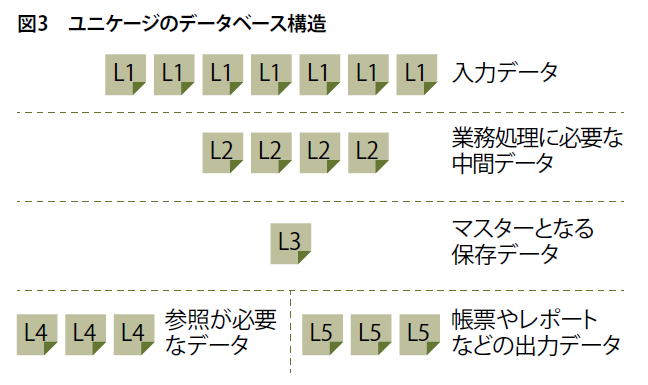
L1は入力データ、L2は業務処理で必要な中間データ、L3はマスターとなるデータ、L4は業務で参照が必要となるデータ、L5は帳票やレポートなどの出力データです。L1~L5には重複したデータが保存されています。一見無駄のように見えますが、業務システムにおいて大きなメリットになります。
L1のデータ
L1では、基本的に一つの入力を一つのファイルで管理しています。
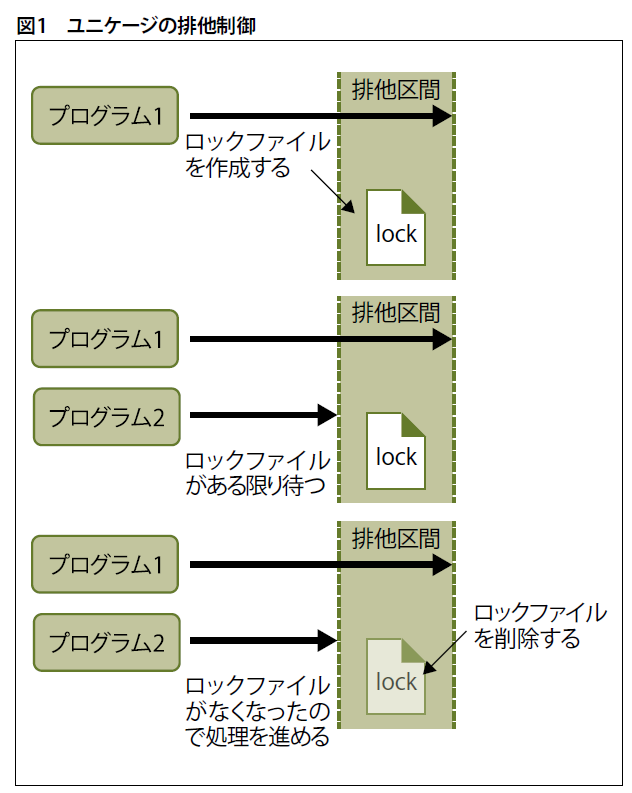
例えば、一つのファイルが1枚の伝票と考えてください。システム内に入力した伝票の状態を残しておけば、もし入力を間違えてしまってもその伝票を差し替えるだけで入力が正しい状態になります。
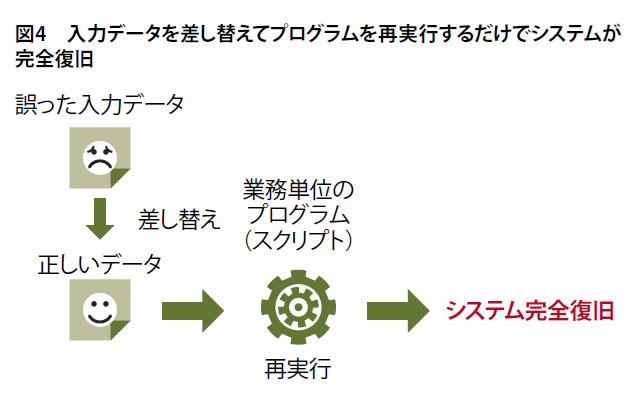
また、ユニケージでは、業務処理ごとに一つのプログラム(シェルスクリプト)を用意します。間違えた伝票がどの業務処理に関係するのかが分かっていれば、対応する一つのプログラムを実行するだけでシステム全体が正しい状態になります。
日々の業務において伝票入力を間違えたり、他のシステムから異常なデータが流れてきたりすることが意外とよくあります。入力した伝票を読み出して修正して再度登録するだけならよいですが、すでに処理済みの場合は、そのデータから作られたデータがどのテーブルのどのレコード(行)のどのカラム(列)にあるかを調べて修正しなくてはいけないなど、面倒な処理が必要になることも考えられます。先に述べたようにユニケージなら該当する入力データのファイルを差し替えてプログラムを実行するだけで済みます(図4)。
L2のデータ
L2は前述した、業務処理で必要な中間的なデータです。このようなデータを用意しておくことで、膨大なマスターデータから必要なデータを抽出しなくてよくなります。素早く業務処理を実行するには欠かせない機能です。
なお、ユニケージのルールでは、このような中間データが不要な場合はL2を作らなくても構いません。
L3のデータ
L3は、データベース管理システムのマスターテーブルと同じです。しかし、L3は常に最新の状態に保つ必要はありません。L1のデータに最新のL3を形作るデータが保存されているからです。
L3は、業務が終わった深夜などに最新の状態に作り直して構いません。業務中に最新の状態にしなければ、L3生成のためのシステム負荷を増やすことなく、システムのリソースを業務処理に集中させられます。
なお、もし業務中に大量の入力があり、それらを加工してL3のデータとして保管する場合、夜間だけでは保管作業が終わらない可能性もあります。ユニケージでは、そのようなことがないように、ユニケージ専用のコマンド群「usp Tukubai」を用意しています。usp Tukubaiでは、インメモリーでCPU固有機能を活用しながら、高速に並べ替えや抽出ができるコマンドを多数提供しています。
L4のデータ
L4は、前述したように業務で参照が必要となるデータです。ただし、伝票処理なら業務終了後に作成した前日のデータになります。そのため、今日入力されたL1のデータと組み合わせることがあります。
人や他のシステムがデータを参照する場合、出力が遅いのはシステムとして致命的です。よって、膨大なマスターデータから抽出せずにL4というデータを用意しておくことは、システムの利便性の面で重要です。
L5のデータ
業務システムで帳票やレポートの出力は大切な機能です。ユニケージでは、その出力をデータベースの中に組み込んでいます。2024年1月から義務化される電帳法などにも対応しやすくなります。
ファイル管理での工夫と優位性
L1~L5のデータすべてがファイルです。各レベルごとに多くのファイルが存在します。ちなみに、複数のファイル内からデータを抽出するのは遅いと感じるエンジニアは多いでしょう。確かにファイルのオープンとクローズは重たい処理です。前述したusp Tukubaiのコマンドを駆使して高速に検索・抽出
を実施しても満足する性能を発揮できないかもしれません。また、膨大なデータとなれば、大きなシステム負荷も発生します。
ユニケージではファイルの中身だけでなく、ファイル名やディレクトリ名などもデータとして利用しています(図5)。
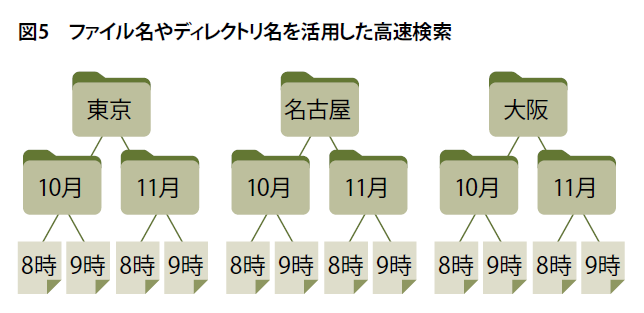
ファイルシステムによるファイルやディレクトリの検索には、Bツリーなどの高速検索アルゴリズムが採用されています。それを活用すれば、ファイルをオープンすることなく高速・低負荷で検索ができ、絞り込んだ後で少なくなったファイルの中身から所望するデータを抽出すればよいわけです。
また、ファイルにはデータベースのテーブルにはないメリットがあります。それは、テキストエディタで開いて中身が読める点です。ユニケージのデータは半角スペースで区切られた表形式で保存されています。
もし、システムから出力されたデータなどにおかしな点を見つけた場合、業務を担当している社員が入力データのファイルを直接確認して問題点を見つけて解決できる可能性があります(図6)。これは、とても早い問題解決につながります。
リレーショナルと大福帳型の両立
もう少しデータベースの仕組みに踏み込んでみます。業務システムのバックエンドで利用されているデータベース管理システムは、一般的に「リレーショナルデータベース管理システム」です。これは、さまざまな属性情報に分けてデータを保存している複数のテーブルを、従業員番号や商品コードなどのキーとなるデータで連携した構造になります。単一のテーブルにすべての情報を登録することなく管理できるので、項目数が多いデータを扱う場合に便利です。ユニケージのデータベースもキーによるデータ連携を実施しています。
このリレーショナルデータベース管理システムでは、データの重複がないようにするための「正規化」、データの永続性を保証する「CRUD」(クラッド)は重要な機能です。ユニケージのデータベースでは、生のデータを保存・管理する点から正規化もCRUDも実施していません。前述したようにL1~L5では重複するデータを保存しています。
CRUDは「Create」(生成)、「Read」(抽出)、「Update」(更新)、「Delete」(削除)の頭文字を取った言葉ですが、ユニケージのデータベースにはUpdateとDeleteが存在しません。では、なぜデータの永続性が保証できるのかといえば、入力日時などでどれが更新・削除されたデータなのかの判別や抽出を可能にしているからです。
ただし、データ量が増えてくると判別や抽出に時間がかかります。そのため、前述のTukubaiコマンド、ファイル名やディレクトリ名、L4のデータなどで高速に処理できるようにしています。
このようにユニケージのデータベースにはリレーショナルデータベース管理システムとしての側面もありますが、BI(Business Intelligence)に使われる大福帳型データベース的な側面があります。近年、業務にかかわるさまざまなデータを分析し、経営戦略に利用している企業が数多く存在します。BIは、その業務分析に使われている言葉です。分析に使われるデータは、日々の業務で発生する情報、つまり業務システムの生データです。
リレーショナルデータベース管理システムのように正規化したデータは分析に活用できません。ユニケージのデータベースでは、日々の業務に必要なデータを提供するとともに生データを蓄積しています。
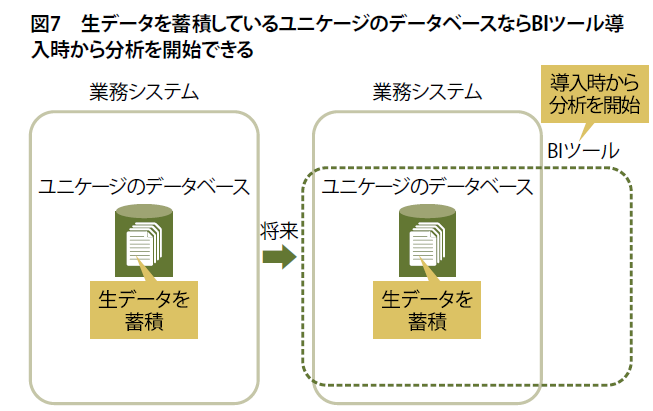
もし、新しい業務システムを構築するときにBIまで手が回らない、また予算が捻出できないとします。リレーショナルデータベース管理システムを採用した業務システムでは、新たにBIツールを導入してからデータを蓄積、データがある程度たまった時点で分析を開始しなくてはいけません。少なくとも1年間のデータを蓄積してからでないと正しい分析ができないでしょう。
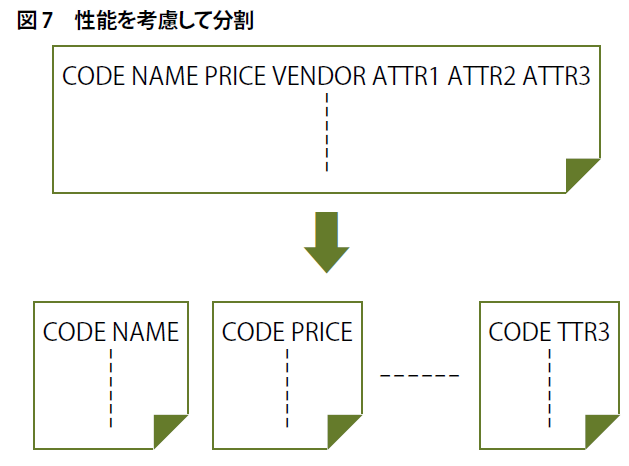
一方、ユニケージなら業務システム構築時に生データを蓄積できる仕組みが用意されています(図7)。新たにBIツールを導入した時点から分析を開始できます。
東京国際フォーラムで2023年9月27日~28日に開催されたイベント「日経クロステックNEXT 東京2023」の特別座談会「検証!失敗の本質~一流企業でなぜITトラブルや品質不正が相次ぐのか」で登壇した日経クロステック編集長の榊原 康氏は、最近頻発しているシステムトラブルに対して「レジリエンス」(回復力)が重要と述べていました。
日々の業務において、人為的トラブルはつきものです。誰でも入力データを理解でき、問題がある箇所を見つけて正しいデータの入力ファイルに差し替えて、プログラムの再実行で修復できるユニケージのデータベースは、レジリエンスが重要な業務システムに合ったものといえるかもしれません。実際に、誤った入力や入力し忘れ、他のシステムからの異常データの受け取りが発生しても入力データの欠落や誤植を修正し、明け方に発生したトラブルも業務開始までには原因究明から完全復旧までを終えている事例が多数存在します。
また、BI的な要素も最近話題のDX(デジタルトランスフォーメーション)では重要です。BIにより業務を可視化することは、すべての企業において必要不可欠になってきています。ユニケージならその点も考慮しながら、通常の業務システムとして開発できます。
著者:ぱぺぽ
※本記事は、シェルスクリプトマガジン Vol.87(2023年12月号)に掲載した記事からの転載です。