written by 高橋光輝
様々なアルゴリズム・機械学習をスマートに組み合わせて未完の短歌の補完を目指した人気連載「機械学習で石川啄木を蘇らせる」。シェルマガでは同人誌から手法を発展させ、新たに記事を書き起こしてもらいました。
連載全体を俯瞰するまとめ回となった最終回を公開します。ぜひお楽しみください!
本連載のもとになった同人誌の内容は、以下のURLから閲覧が可能です。(編集部)
https://sunpro.io/c89/pub/hakatashi/introduction

遂に、機械学習で石川啄木が帰り来れり
こんにちは。高橋光輝(HN:博多市)です。今回は連載「機械学習で石川啄木を蘇らせる」の最終回として、今までに生成した、「啄木の短歌」と「ダミーの短歌」の素性ベクトルをもとに、「啄木らしさ」を学習します。その後前々回作成した「最後の一首」候補の短歌を分類器にかけ、最も「啄木らしさ」の高い一首を、復元された「最後の一首」とします。
さて、前回までの作業で「啄木の短歌」と「ダミーの短歌」の素性ベクトルを抽出し、それぞれの短歌が持つ特徴を100次元のベクトルデータに変換することができました。このように入力データを正規化し形式を揃えることによって、機械学習にとって扱いやすいデータになります。今回は「啄木の短歌」と「ダミーの短歌」を正確に分類できる分類器を作成することによって、擬似的に「啄木らしさ」の学習を行っていきます。
以前お話したとおり、分類問題は機械学習の最も基本的なタスクです。機械学習の草創期から現在に至るまで非常に多くのモデルが提唱されてきました。この連載のもととなった記事では多項ナイーブベイズ分類器を用いて分類を行いましたが、今回の連載では線形サポートベクトルマシンを用いた分類器を使用することにしました。一般に機械学習においてどのようなタスクにどのような手法が向いているのかというのを理論的に示すのは難しく、パラメーターの調整次第でいくらでも性能が変化しうるというのが機械学習の難しい部分です。今回の場合も理論的にどうこうというよりは試行錯誤を重ねたうえでの選択となっていますので、このあたりの説明の足りない点はどうかご容赦ください。
SVMをこのごろ気になる
さて、サポートベクトルマシン、略してSVMというのは少しでも機械学習を齧ったことがある方なら一度は聞いたことのある名前でしょうが、あらためて軽く解説を行いたいと思います。
SVMはおそらく、数ある機械学習のモデルの中でも特に直感的に理解しやすいモデルです。図1のように、ベクトル空間上に分類したい2種類のデータが点在する状況を考えます。これらのデータを元に未知のデータに対して分類を行うには、ベクトル空間のどの部分がどの種類のデータの領域なのかを定める境界面、つまり識別面が必要になります。
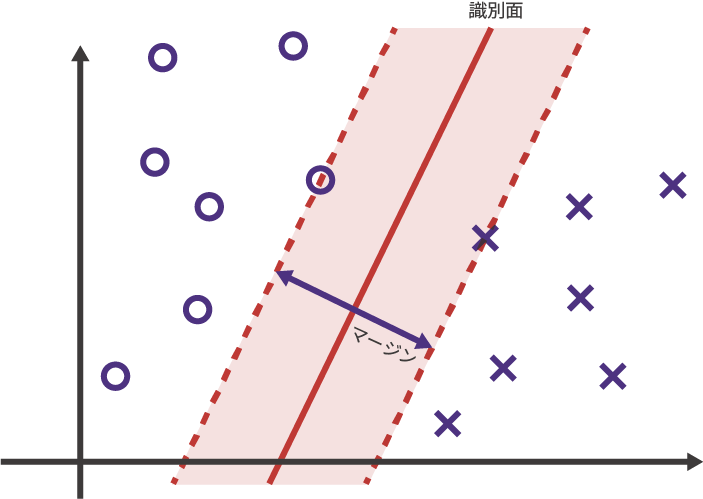
図1:SVMによる識別面の設定
SVMはこの識別面を、それぞれのクラス中で最も識別面に近いデータまでの距離、つまりマージンが最大化されるように線を引きます。この識別面の具体的な引き方を計算するには線形代数の知識が必要であるためここでは省略しますが、通常のデータでは入力されたデータからこのような識別面の解を一意に求めることができます。これが線形サポートベクトルマシンにおける「学習」です。
こんな単純なモデルで本当に「啄木らしさ」が学習できるのかと疑問に思うかもしれません。実際、線形SVMによる分類は名前の通り線形であり、非線形な処理を含まないため単体では表現力に乏しいとされています。しかし、今回分類するデータは、word2vecとsentence2vecを用いてベクトルに落とし込む段階ですでに言語の意味論的な部分をベクトル空間上に抽象化していると考えられるでしょう。word2vecによる事前学習を行ったデータがSVMやK-meansなどの比較的単純な手法でも非常に高いスコアを上げることはword2vecを提唱した論文でも示されており、これが今回のケースにも当てはまります。つまり、単語からベクトル空間へのよく学習された写像関係においては、たかだか100程度の次元で言語が持つ複雑な意味論的モデルを十分に表現できるということであり、この点からもword2vecの優秀さを伺うことができます。
SVMにさはりてみるかな
さて、話は脱線しましたが、ここからは実際にSVMを用いて「啄木の短歌」と「ダミーの短歌」を分類する分類器の学習を行いましょう。今回はscikit-learnというライブラリを使用します。scikit-learnは、機械学習の様々なモデルや、機械学習をする上で便利なツールが1つのパッケージに実装したライブラリであり、多種多様な機械学習を手軽に試せるため、機械学習の定番的なライブラリとなっています。一方、速度などの点では他のライブラリにやや劣っていますが、今回は学習するデータ数が比較的少ないため問題にはならないでしょう。
scikit-learnをインストールするために、次のコマンドを打ち込んでください。
|
1 |
$ pip install scikit-learn |
では、コードを書いていきます。いつも通り、Makefileの最初にリスト1のような行を加えてください。
|
1 2 3 |
.PHONY: print-predicted-tanka print-predicted-tanka: predict_takuboku_tanka.py tanka-dummy-vectors.txt tanka-takuboku-vectors.txt tanka-vectors.txt $(PYTHON) $^ |
そして、predict_takuboku_tanka.pyというファイルを作成し、次のように記述します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
# -*- coding: utf-8 -*- import sys import csv from sklearn.svm import SVC from sklearn.model_selection import cross_val_score import numpy as np # 引数の数をチェック if len(sys.argv) != 4: print('This program must be called with 4 arguments') sys.exit() # 引数からファイル名を取得 [this_file, dummy_vectors_file, takuboku_vectors_file, tanka_vectors_file] = sys.argv # ファイルから短歌のベクトルデータを読み取る dummy_vectors = np.loadtxt(dummy_vectors_file, delimiter=' ') takuboku_vectors = np.loadtxt(takuboku_vectors_file, delimiter=' ') tanka_vectors = np.genfromtxt(tanka_vectors_file, delimiter=' ', dtype=None) # ダミーの短歌と啄木の短歌を結合して入力データとして整形 X = np.concatenate((dummy_vectors, takuboku_vectors)) y = np.concatenate((np.zeros(len(dummy_vectors)), np.ones(len(takuboku_vectors)))) # 学習精度を測るための分類器を用意 pre_classifier = SVC(kernel='linear') # 5分割交差検定で学習精度を計測 scores = cross_val_score(pre_classifier, X, y, cv=5) # 計測したスコアを報告 print('SVM Score:', scores.mean()) # 同じパラメータで今度はすべての入力データを用いて学習を行う classifier = SVC(kernel='linear', probability=True) classifier.fit(X, y) # 「最後の一首」候補の短歌をラベルデータとベクトルデータに分割 tanka_vectors_labels = np.array([list(row)[0] for row in tanka_vectors]) tanka_vectors_data = np.array([list(row)[1:] for row in tanka_v ectors]) # 分類器を用いて学習し、それぞれの「啄木の短歌らしさ」を推定する proba = classifier.predict_log_proba(tanka_vectors_data) # 「啄木の短歌らしさ」の高い順に並べる sorted_proba = np.array(sorted(zip(proba, tanka_vectors_labels), key=lambda r:r[0][1])) # 上位30件を報告 print('\n'.join(['{0:>2}. {1}'.format(i + 1, p[1].decode("utf-8")) for i, p in enumerate(sorted_proba[:30])])) |
ここで、分割交差検定と呼ばれる方法を用いてSVMの精度を測定しています。分類器の精度とはすなわち分類の正確さであり、既知のデータに対してどれだけ正確に分類を行えるかを計測することによって測定できますが、このとき学習に用いたデータを測定に使用しないよう注意が必要です。学習に用いたデータは学習機にとっても既知のデータであり、正確に分類を行えるのはある意味当然であるので、精度測定が不正確になるおそれがあります。そのため、通常はデータセットを学習用のデータとテスト用のデータに分割して使用するのですが、このときの分割の仕方によって精度測定に影響が出る可能性があるため、学習用のデータとテスト用のデータを互いに入れ替えながら何度も測定を行うことがあります。これが分割交差検定です。
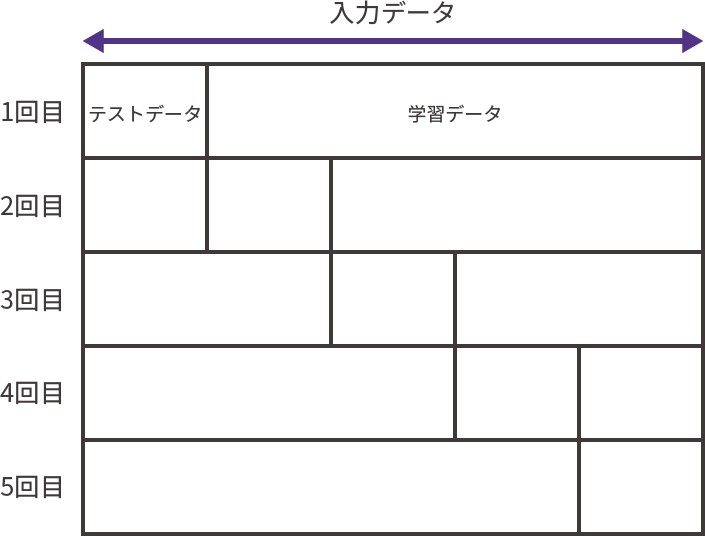
図2:5分割交差検定の例
今回の測定では5分割の交差検定を行っています。つまり、入力データの5分の1をテストデータに使用する測定を5回行っているということです。この測定結果は環境や乱数によって多少変動するでしょうが、おおむね97~98%程度の数値が出ると思われます。これはこの連載の元となった記事での93.3%という精度と比較しても非常に高いスコアであり、「啄木の短歌」と「ダミーデータ」との違いがよく学習ができていることが期待されます。
プログラムではその後、あらためてすべての入力データを用いてSVMの学習を行い、本命の「最後の一首」の候補を分類するための分類器を学習します。そして、それが終わったら実際にこれまでの連載で作成してきた「最後の一首」候補の短歌のベクトルデータを分類器に入力し、「啄木の短歌らしさ」の数値を推定します。これによって最もスコアが高かったものが、復元された「啄木の最後の一首」ということになります。
大跨に椽側を歩けば……
長い道のりでしたが、ようやく復元結果の発表です。それではもったいぶらずに発表しましょう。機械学習の力を借りて現代に蘇った石川啄木の最後の一首、その内容はこちらに決定しました。
大跨に椽側を歩けば、
うしなひしをさなき心
寄する日ながし。
……いかがでしょうか? 実のところ生成時に関係するさまざまな環境や乱数によって生成される短歌が異なる可能性があるので、これが唯一の解答というわけではありません。読者の皆さんが試した結果はこれとは異なる可能性があります。それぞれにそれぞれの復元結果があるということです。
「啄木らしさ」が高いと判定された短歌がどのようなものか確認するために、スコアの高かった上位30件を順に見てみましょう。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
1. 大跨に椽側を歩けばうしなひしをさなき心寄する日ながし 2. 大跨に椽側を歩けば生命が身によりかかり眼閉ぢ眼をとづ 3. 大跨に椽側を歩けばうしなひしわが来しかたのをかしく悲し 4. 大跨に椽側を歩けば呆れ喉かなしみたる気自分の主筆さ 5. 大跨に椽側を歩けばこれ見よと鳴きて走らせし母としたしむ 6. 大跨に椽側を歩けばこれ見よと入日うつれるかなしき日ながし 7. 大跨に椽側を歩けばのめる時とつたへと銭のなかのなつかし 8. 大跨に椽側を歩けばおのづから目さまして見る玩具の機関車 9. 大跨に椽側を歩けばむなしきつつつき鉢寒き煉瓦何かな 10. 大跨に椽側を歩けば字に四百いひ出でかかり初雪心 11. 大跨に椽側を歩けば煙草のみ考へるわれのこころ冷たし 12. 大跨に椽側を歩けば胸いたみ春の多きこと聞けばおとなし 13. 大跨に椽側を歩けば逃げてゆきしわが来しかたのをかしく悲し 14. 大跨に椽側を歩けばこの前をとづ高きなき出さより眠る 15. 大跨に椽側を歩けばこれ見よとかしこみて見る玩具の機関車 16. 大跨に椽側を歩けばおのづから目さませばからだ痛くてみたし 17. 大跨に椽側を歩けばうしなひし草稿の字の読みがたさかな 18. 大跨に椽側を歩けば今日とわかれ読む度ところ従兄ぬ 19. 大跨に椽側を歩けば泣いてゆきしわが来しかたのをかしく悲し 20. 大跨に椽側を歩けば誦しなしの夜目には軽くかろく眺むる 21. 大跨に椽側を歩けばうしなひし大という字の読みがたさかな 22. 大跨に椽側を歩けばこれ見よとかしこみて見る玩具の機関車 23. 大跨に椽側を歩けば高く笑ひ身をば寄せたる淡き見覚え 24. 大跨に椽側を歩けばいつ見つつわれよりえらく見ゆる日ながし 25. 大跨に椽側を歩けば煙草かな寝つ起きつし後酒に射し入る 26. 大跨に椽側を歩けば友なみだ垂れ手にためし雪のあけぼの 27. 大跨に椽側を歩けば病人の目さましてやや長きキスをやる 28. 大跨に椽側を歩けばなつかしき降れ年深夜の煙かくしは 29. 大跨に椽側を歩けばかなしきに穿く鳥口を人すこし寝り 30. 大跨に椽側を歩けば住みとるる問ふを見口に力し泣き読む |
全体としての印象は、「かなしき」「うしなひし」「むなしき」「痛く」「冷たし」といった陰的な形容が目立ちます。この点は非常に興味深いです。以前紹介した復元結果「大跨に椽側を歩けば、板軋む。/かへりけるかな――/道広くなりき。」では「椽側を歩く」という表現から「板軋む」「道広く」といった意味的な共起表現を拾っており、この点で以前の結果は優れていましたが、一方で詩的表現の手段としての言語をあまりにも字句的に捉えすぎているという指摘も受けました。今回の結果は前回よく見られたような「板」や「道」のような前半と関連する表現は見受けられませんが、代わりにこのような精神的な表現の傾向が陽に現れたことは、ある種前回の壁を乗り越えられたといえるのではないでしょうか。
また、「眼閉ぢ眼をとづ」や「軽くかろく眺むる」といった同じ単語の繰り返しのパターンが現れているのも興味深いです。三十一文字の中で同じ表現や単語を繰り返すのは特に前期啄木に見られる技法であり、「なみだなみだ/不思議なるかな/それをもて洗へば心戯けたくなれり」「はたらけど/はたらけど猶わが生活楽にならざり/ぢっと手を見る」といった歌にみることができます。この結果に出てきている用例はかなり露骨でありあまり高く評価はできませんが、もしかしたらこのような表現パターンを入力データから学習しているのかもしれません。
というわけで、今回の復元結果はこのようになりましたが、この結果は学習のパラメータや手法次第で大きく変わる可能性があります。読者の皆さんはぜひ、各種パラメーターを変更して、より望ましい結果が得られるように調整してみてください。たとえば、
・形態素解析に用いる辞書データの変更
・RNNLMやマルコフ連鎖で生成する短歌の数の変更
・マルコフ連鎖で用いるn-gram辞書のnの値の変更
・RNNLMに渡す各種パラメーター
・分類器のパラメーターの変更、もしくは探索※2
などは試してみる価値があると思います。
ひよつとした事が、思ひ出の種にまたなる
さて、こうして無事石川啄木の最後の一首を復元することができたので、おさらいをする意味も込めて本連載の流れをもう一度最初から振り返ってみましょう。
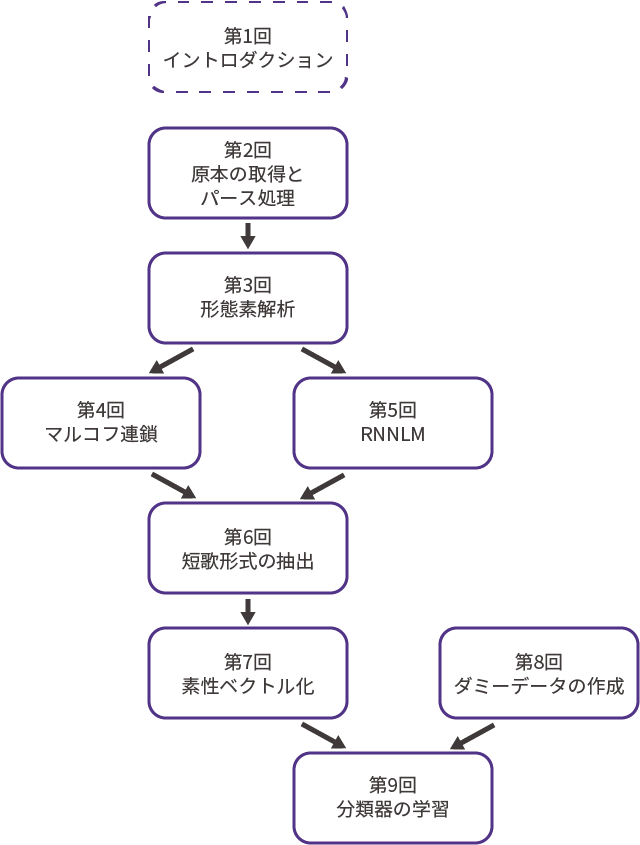
第1回(編:本誌 vol.38掲載)では、イントロダクションとして、本連載の中心人物である石川啄木の紹介、そして石川啄木の未完の「最後の一首」の解説を行いました。
第2回(vol.39)では「最後の一首」復元の第一歩として、青空文庫から原本となる啄木のテキストを取得し、短歌の部分を切り出してパースする処理を行いました。
第3回(vol.40)では、第2回でパースしたデータを形態素解析にかけ、短歌がどのような語句で構成されているのかを解析しました。
第4回(vol.41)では、第3回で形態素解析したデータを元にマルコフ連鎖を行い、文章としての繋がりを重視するプローチから「最後の一首」候補を作成しました。
第5回(vol.42)は第4回と並行する形で、今度はRNNLMを用いて「最後の一首」候補を作成しました。こちらはどちらかというと文脈を重視したアプローチになります。
第6回(vol.43)では、第4回と第5回で作成した「最後の一首」候補から、短歌の形式をとっているものをフィルタリングする処理を行いました。ここで単語列を文節に分けるテクニックを解説しました。
第7回(vol.44)では、短歌形式を取っている「最後の一首」候補を、word2vecとsentence2vecを用いて素性ベクトルに変換し、機械学習で扱いやすい形に変換しました。
第8回(vol.45)では機械学習による分類を行うための前準備として、「石川啄木らしくないデータ」、つまりダミーデータを生成する処理を行いました。また実装は行いませんでしたが、類似技術であるGANについても同時に解説を行いました。
そして第9回となる今回では、第8回で生成したダミーデータと啄木の短歌を正確に分類するSVMを学習し、それを用いて第7回で生成した啄木の「最後の一首」候補の「啄木らしさ」を推定し、もっとも「啄木らしさ」の高い一首を復元された「最後の一首」としました。
こうしてみると、「石川啄木の最後の一首を復元する」という一つのタスクに対して、様々な技術が複雑に関係していることがわかります。啄木の歌集の校訂者に端を発し、形態素解析器、マルコフ連鎖、RNNLM、word2vec、SVMと、どれも偉大な先人が築き上げてきた技術の集大成です。現代に生きる我々の使命は、折りに触れてなるべく広範な知識を身に着け、こうして巨人の肩の上に立ち、その上でどれだけ新しい価値を生み出せるかということに懸かっていると思って止みません。みなさんもこの連載記事を通じて、石川啄木や自然言語処理、さらに機械学習に興味を持って頂けると幸いです。
それでは、以上で連載「機械学習で石川啄木を蘇らせる」最終回とさせていただきます。9回の長い間お付き合いくださりありがとうございました。また機会があればどこかで会いましょう。
あなたにとっての技術が、物語のよき隣人でありますように。
本記事は、シェルスクリプトマガジンvol.38~vol.46に掲載された連載の最終回です。それぞれの技術の詳細については、該当のバックナンバーをご参照ください。(編集部)


![]()
![]()
 →
→  →
→  →
→  →
→ 

 「ゴミが落ちてるぞ!」
「ゴミが落ちてるぞ!」 「拾って写メを撮って…」
「拾って写メを撮って…」 「ピリカに投稿だ」
「ピリカに投稿だ」 「拾ったゴミはゴミ箱へ」
「拾ったゴミはゴミ箱へ」 (数時間後)「お、【ありがとう】がたくさんついてる。いいことした気分!またゴミが拾いたくなってきた」
(数時間後)「お、【ありがとう】がたくさんついてる。いいことした気分!またゴミが拾いたくなってきた」

