ユニケージ通信(第2回)
よく使うUNIX/Linuxコマンド
業務システム開発手法の「ユニケージ」では、データベース管理システムやフレームワークなどを使わずにシステムを構築します。システムの中身が見えやすい分、仕組みやルールを理解していないと正しい開発ができません。第2回はよく使うUNIX/Linuxコマンドと、既存データの変換を紹介します。
前回は、ユニケージのファイル管理について簡単に解説しました。今回はまず、ユニケージによるファイル処理に必要なUNIX/Linuxコマンドを紹介します。その後で、既存のデータベースのテーブルからデータを取り出してユニケージで扱うための準備をします。
UNIX/Linuxコマンドを使うわけ
前回述べたように、ユニケージでは主なプログラムを「シェルスクリプト」として記述します。シェルスクリプトは、UNIX/Linuxコマンドの集まりです。
UNIXおよびLinuxでは、端末からコマンドを入力してファイル内のデータを取り出したり、加工して別ファイルに保存したり、同じファイルに上書きしたりする処理をよく使います。ユニケージでは、この特徴を生かすことで、業務ロジックはJava、PHP、JavaScriptなどの言語、データベース管理システム
(DBMS)へのアクセスはSQL文などと分ける必要がなく、シェルスクリプト内のUNIX/Linuxコマンドですべての処理を実現しています(図1)。

なお、UNIX/Linuxコマンドだけで業務ロジックを記述するのは、簡単ではありません。よって、業務処理によく使う専用のコマンド群として「usp Tukubai」を用意しています。
よく使うUNIX/Linuxコマンド
UNIXやLinuxの端末にコマンドを入力すると、「シェル」というプログラムがコマンドを解釈してOS(カーネル)に対して実行に必要な処理を依頼します。依頼した処理がすべて完了した時点でコマンドの実行が終わります。シェルスクリプトでは、このような処理を先頭行から順に1行ずつ行っています。
シェルには「Bash」(bash)、「C shell」(csh)、「Z shell」(zsh)などのいくつか種類があります。ユニケージでは、Linuxの標準シェルであるBashを利用しています。特に、Bashに用意されているコマンドの中で、ユニケージでは次のものをよく使います。
echo/dateコマンド
「echo」は文字列や数値、変数値を出力するコマンドです(図2)。「date」は年月日と時刻の表示や設定をするコマンドです(図3)。

cat/cp/mv/rm/mkdirコマンド
「cat」「cp」「mv」「rm」「mkdir」は、ファイルやディレクトリを操作するコマンドです(図4)。catは複数のファイルを連結するコマンド、cpはファイルやディレクトリをコピーするコマンド、mvはファイルやディレクトリを移動するコマンド、rmはファイルやディレクトリを削除するコマンド、mkdirはディレクトリを作成するコマンドです。
なお、catコマンドはファイルの中身を出力するときにも利用します。

head/tailコマンド
「head」は先頭から、「tail」は末尾から行単位でテキストファイルの内容を取り出すコマンドです(図5)。

grepコマンド
「grep」は指定した文字列(正規表現で表した文字列)を含む(あるいは含まない)行をテキストファイル内から抽出して出力するコマンドです(図6)。

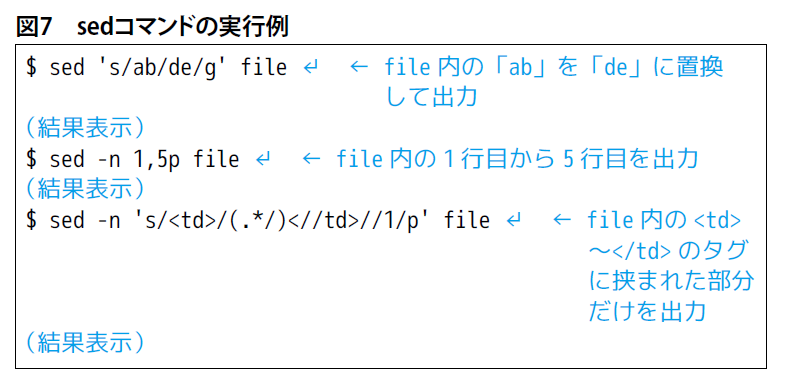
sedコマンド
「sed」はテキストファイル内の文字列を置換したり、行単位で抽出したり、削除したりするコマンドです(図7)。
awkコマンド
「awk」は、プログラミング言語「AWK」で記述したプログラムを実行するコマンドです(図8)。AWKはテキストファイルの加工処理に向いた言語で、古くからシェルスクリプト内で利用されています。

標準入力/標準出力/標準エラー出力
UNIX/Linuxコマンドの出力先や入力先として「標準入力ファイル」「標準出力ファイル」「標準エラー出力ファイル」があります。これらのファイルを操作する場合に識別子となる「ファイルディスクリプタ」を利用します。このファイルディスクリプタですが、標準入力ファイルが「0」、標準出力ファイルが「1」、標準エラー出力ファイルが「2」になります。
なお、デフォルトでは「0」がキーボード入力に、「1」と「2」が端末に結び付けられています。図2の「echo a b c」では、キーボードで入力されたコマンドを実行した結果の「a b c」が端末上に表示されています。
コマンドで標準入力、標準出力、標準エラー出力を扱う上で次に紹介する「リダイレクト」「パイプ」をよく使います。
リダイレクト
リダイレクトは「>」「<」「>>」の記号で表すコマンドです。別のコマンドに対してファイルの中身を入力として渡したり、コマンドの出力内容をファイルに書き出したりするときに使います(図9)。

パイプ
パイプは「|」の記号で表すコマンドです。二つのコマンドの出力と入力を連結するときに利用します。例えば、fileファイルの先頭100行と末尾10行を切り取って出力するには、
$ head -100 file | tail -10 ↵のように実行します。パイプで「head -100 file」を実行した結果を「tail -10」に渡しています。
テーブルからデータ取り込み
ユニケージでシステムを構築する手始めとして、データベースのテーブル上にある既存データを取り込むことがよくあります。この作業にもコマンドを利用します。
その準備として、データベース管理システム(DBMS)の機能やコマンドを利用してテーブルをCSV形式のファイルに変換して出力します。CSVとはComma Separated Valuesの略で、各行(レコード)のデータを列(カラム)ごとにカンマ(, )で区切ったテキストです。前回も触れましたが、ユニケージのデータファイルでは各行のデータがカンマではなく半角スペースで区切られています。ユニケージで扱うにはカンマを半角スペースに変換しないといけません。さらに、半角スペースを含むデータの「”」(ダブルクオーテーション)を取り除いたり、半角スペースを「_」(アンダーバー)に変換したりも必要です。
WindowsなどのOSではテキストファイルの文字コードや改行コードがUNIX/Linuxと異なります。そのため、文字コードや改行コードの変換が必要な場合もあります。なお、UNIX/Linux上のデータベースのテーブルなら文字コードと改行コードの変換は不要です。また、半角のアルファベットや数字、記号のみのデータを保存したテーブルであれば、文字コードの変換が不要です。
それでは順に作業を進めていきましょう。CSV形式で出力したファイルを「TABLE.CSV」とします。先ほどの文字コードの違いからCSV形式のファイルに出力するときのファイル名には、半角のアルファベットや数字を用いてください。例にしたテーブルは、Windows内のデータベースから取り出しました。 catコマンドでCSV形式のファイルの中身を確認してみると、図10のように日本語の文字列が含まれているので文字が化けています。Windowsの文字コード*1は、シフトJISに機種依存文字を追加した「コードページ932」(CP932)です。それに対して、UNIX/Linuxの文字コードは「UTF-8」です。この違いにより、文字化けが発生しています。

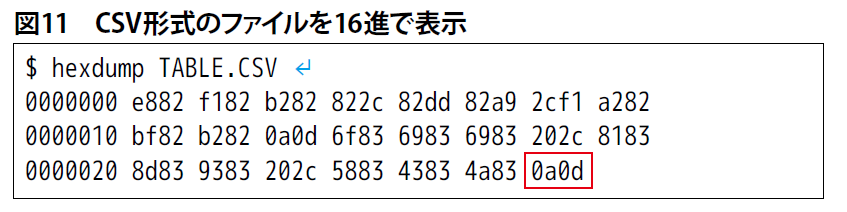
改行コードは表示されないので、「hexdump」コマンドで16進に変換して確認します(図11)。最後に「0a0d」があります。「0d」はCR、「0a」はLFのコードで、これはWindowsの改行コードです。UNIX/Linuxの場合は「0a」のLFのみになります。
ユニケージのデータファイル形式に変換する前に文字コードと改行コードを変換します。それには、UNIX/Linuxコマンドである「uconv」を使います。「-stou」はシフトJISからUTF-8へ変換するオプション、「-Lu」はUNIX/Linuxの改行コードに変換するオプションです*2。
$ uconv -Lu -stou TABLE.CSV ↵
りんご,みかん,いちご
バナナ, メロン, スイカ変換した結果は、端末上に出力されます。この出力結果を「fromcsv」コマンドにパイプで渡すとユニケージのデータファイル形式に変換されます。このfromcsvは、usp Tukubaiに含まれている、ユニケージのコマンドです。
$ uconv -Lu -stou TABLE.CSV | fromcsv ↵
りんご みかん いちご
バナナ メロン スイ最後に、リダイレクトを使ってファイル(ここでは「TABLE」)に書き込めば、ユニケージのデータファイルが完成します。
$ uconv -Lu -stou TABLE.CSV | fromcsv > TABLE ↵次回は、ユニケージのデータファイルからデータを取り出してSQL文のように操作する方法を紹介します。
*1 実は、Windowsも内部はUTF-8を利用しています。しかし、日本語を使用するユーザーが扱う文字コードは、標準でCP932になっています。
*2 機種依存文字は変換できないのでシフトJISからUTF-8への変換で構いません。
著者:田渕 智也、高橋 未来哉
※本記事は、シェルスクリプトマガジン Vol.82(2023年2月号)に掲載した記事からの転載です。